This is the multi-page printable view of this section. Click here to print.
Blog
- Guided Open Cluster Management Install with KubeStellar Console
- Cluster Proxy Now Supports "Service Proxy" — An Easy Way to Access Services in Managed Clusters
- Open Cluster Management 社区诚邀您共赴 KubeCon China 2025 探讨多集群管理新未来
- Joining OCM Hub and Spoke using AWS IRSA authentication
- KubeCon NA 2024 - Scheduling AI Workload Among Multiple Clusters
- KubeDay Australia 2024 - Open Sourcing the Open Cluster Management Project and the Lessons We Can Learn for AI
- KubeCon CN 2024 - Boundaryless Computing: Optimizing LLM Performance, Cost, and Efficiency in Multi-Cloud Architecture | 无边界计算:在多云架构中优化LLM性能、成本和效率
- KubeCon CN 2024 - Connecting the Dots: Towards a Unified Multi-Cluster AI/ML Experience | 连接点:走向统一的多集群AI/ML体验
- KubeCon CN 2024 - Extend Kubernetes to Edge Using Event-Based Transport | 使用基于事件的传输将Kubernetes扩展到边缘
- The HA Hub clusters solution -- MultipleHubs
- Using the GitOps way to deal with the upgrade challenges of multi-cluster tool chains
- Open Cluster Management - Configuring Your Kubernetes Fleet With the Policy Addon
- 以GitOps方式应对多集群工具链的升级挑战
- 详解OCM add-on插件
- 使用OCM让多集群调度更具可扩展性
- How to distribute workloads using Open Cluster Management
- KubeCon NA 2022 - OCM Multicluster App & Config Management
- KubeCon NA 2022 - OCM Workload distribution with Placement API
- Karmada and Open Cluster Management: two new approaches to the multicluster fleet management challenge
- Extending the Multicluster Scheduling Capabilities with Open Cluster Management Placement
- 详解ocm klusterlet秘钥管理机制
- 通过OCM访问不同VPC下的集群
- Using the Open Cluster Management Placement for Multicluster Scheduling
- Using the Open Cluster Management Add-on Framework to Develop a Managed Cluster Add-on
- The Next Kubernetes Frontier: Multicluster Management
- Put together a user walk through for the basic Open Cluster Management API using `kind`, `olm`, and other open source technologies
- Setting up Open Cluster Management the hard way
Guided Open Cluster Management Install with KubeStellar Console
Installing Open Cluster Management (OCM) involves multiple steps — adding Helm repos, installing the control plane, registering managed clusters, and verifying everything works. KubeStellar Console now includes a guided install mission that walks you through the entire process step-by-step, with built-in validation and troubleshooting.
What is KubeStellar Console?
KubeStellar Console is a standalone, open-source Kubernetes dashboard with 30+ dashboards and 150+ monitoring cards. It connects to your clusters via kubeconfig and includes an AI-powered mission system that provides guided workflows for installing and managing CNCF projects.
Note: KubeStellar Console is unrelated to the KubeStellar multi-cluster orchestration project — they share a name but have zero shared code.
The OCM Install Mission
The OCM install mission runs against your live cluster. Each step includes:
- Pre-flight checks — verifies prerequisites (Kubernetes >=1.24, Helm, kubectl)
- Exact commands — shows the
helm installandkubectl applycommands with flags explained. Copy-paste or run directly from the console - Validation — after each step, queries your cluster to verify success (pod phase, CRD registration, service endpoints)
- Troubleshooting — on failure, reads pod logs, events, and resource status and suggests fixes
- Rollback — each step includes the corresponding
helm uninstall/kubectl deleteto undo
It also works as read-only documentation — no cluster connection required to browse the steps.
Try It
Option 1: Browse Online
Open the mission directly at:
console.kubestellar.io/missions/install-open-cluster-management
Option 2: Run Locally
Install KubeStellar Console locally (connects to your current kubeconfig context):
curl -sSL https://raw.githubusercontent.com/kubestellar/console/main/start.sh | bash
Then navigate to the OCM install mission from the Missions page.
Contributing
The mission definition is open source at console-kb. PRs to improve the OCM install steps are welcome.
KubeStellar Console currently has 180+ install missions covering CNCF projects across the landscape. If you’d like to see missions for other OCM-related projects or have suggestions for improving the OCM mission, open an issue on kubestellar/console-kb.
Cluster Proxy Now Supports "Service Proxy" — An Easy Way to Access Services in Managed Clusters
Introduction
Cluster Proxy is an OCM addon that provides L4 network connectivity between hub and managed clusters through a reverse proxy tunnel. In previous versions, accessing services on managed clusters through cluster-proxy required using a specialized Go package, the konnectivity client.
With the new v0.9.0 release, we’ve introduced a more convenient approach — “Service Proxy”. This feature provides an HTTPS service that allows users to access the kube-apiserver and other services in managed clusters through a specific URL structure. Additionally, it introduces a more user-friendly authentication and authorization mechanism using Impersonation, enabling users to authenticate and authorize against the managed cluster’s kube-apiserver using their hub user token.
Let’s set up a simple test environment to demonstrate these new capabilities.
Setting Up the Environment
First, create a basic OCM environment with one hub cluster and one managed cluster.
Create a hub cluster with port mapping for the proxy-entrypoint service. The extraPortMappings configuration exposes port 30091 from the container to the host machine, allowing external access to the proxy service:
# Create hub cluster with port mapping for proxy-entrypoint service
cat <<EOF | kind create cluster --name "hub" --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30091
hostPort: 30091
protocol: TCP
EOF
# Create managed cluster
kind create cluster --name "managed"
# Initialize the OCM hub cluster
echo "Initializing the OCM hub cluster..."
clusteradm init --wait --context kind-hub
# Get join command from hub
joincmd=$(clusteradm get token --context kind-hub | grep clusteradm)
# Join managed cluster to hub
echo "Joining managed cluster to hub..."
$(echo ${joincmd} --force-internal-endpoint-lookup --wait --context kind-managed | sed "s/<cluster_name>/managed/g")
# Accept the managed cluster
echo "Accepting managed cluster..."
clusteradm accept --context kind-hub --clusters managed --wait
# Verify the setup
echo "Verifying the setup..."
kubectl get managedclusters --all-namespaces --context kind-hub
Installing Cluster Proxy
Next, install the Cluster Proxy addon following the official installation guide:
helm repo add ocm https://open-cluster-management.io/helm-charts/
helm repo update
helm search repo ocm/cluster-proxy
Verify that the CHART VERSION is v0.9.0 or later:
$ helm search repo ocm/cluster-proxy
NAME CHART VERSION APP VERSION DESCRIPTION
ocm/cluster-proxy 0.9.0 1.1.0 A Helm chart for Cluster-Proxy OCM Addon
Setting Up TLS Certificates
The new deployment cluster-proxy-addon-user requires server certificates for its HTTPS service, otherwise the deployment will hang in the container creating state:
To create the certificates, first install cert-manager:
kubectl --context kind-hub apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.17.0/cert-manager.yaml
kubectl --context kind-hub wait --for=condition=ready pod -l app.kubernetes.io/instance=cert-manager -n cert-manager --timeout=300s
Next, create the certificate resources using the kind cluster’s root CA. This approach allows all pods and services in the kind cluster to automatically trust the cluster-proxy certificates without requiring additional CA certificate mounting:
# Create namespace and certificates using kind cluster's CA
kubectl --context kind-hub create namespace open-cluster-management-addon
CA_CRT=$(kubectl --context kind-hub config view --raw -o jsonpath='{.clusters[?(@.name=="kind-hub")].cluster.certificate-authority-data}')
CA_KEY=$(docker exec hub-control-plane cat /etc/kubernetes/pki/ca.key | base64 -w 0)
kubectl --context kind-hub apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: kind-cluster-ca
namespace: open-cluster-management-addon
type: kubernetes.io/tls
data:
tls.crt: ${CA_CRT}
tls.key: ${CA_KEY}
---
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: kind-ca-issuer
namespace: open-cluster-management-addon
spec:
ca:
secretName: kind-cluster-ca
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: cluster-proxy-user-serving-cert
namespace: open-cluster-management-addon
spec:
secretName: cluster-proxy-user-serving-cert
duration: 8760h # 1 year
renewBefore: 720h # 30 days
commonName: cluster-proxy-addon-user.open-cluster-management-addon.svc
dnsNames:
- cluster-proxy-addon-user
- cluster-proxy-addon-user.open-cluster-management-addon
- cluster-proxy-addon-user.open-cluster-management-addon.svc
- cluster-proxy-addon-user.open-cluster-management-addon.svc.cluster.local
privateKey:
algorithm: RSA
size: 2048
issuerRef:
name: kind-ca-issuer
kind: Issuer
EOF
Verify the secret is created:
kubectl --context kind-hub get secret -n open-cluster-management-addon cluster-proxy-user-serving-cert
Installing the Cluster Proxy Helm Chart
Now install the cluster-proxy addon with the necessary configuration:
# Set the gateway IP address for the proxy server
# This is the Docker gateway IP that allows the Kind cluster to communicate with services
# running on the host machine. The managed cluster will use this address to connect
# to the proxy server running in the hub cluster.
GATEWAY_IP=$(docker inspect hub-control-plane --format '{{.NetworkSettings.Networks.kind.IPAddress}}')
kubectl config use-context kind-hub
helm install -n open-cluster-management-addon --create-namespace \
cluster-proxy ocm/cluster-proxy \
--set "proxyServer.entrypointAddress=${GATEWAY_IP}" \
--set "proxyServer.port=30091" \
--set "enableServiceProxy=true"
To expose the proxy server to the managed clusters, we need to create a service that makes the proxy server accessible from the external network.
cat <<'EOF' | kubectl --context kind-hub apply -f -
apiVersion: v1
kind: Service
metadata:
name: proxy-entrypoint-external
namespace: open-cluster-management-addon
labels:
app: cluster-proxy
component: proxy-entrypoint-external
spec:
type: NodePort
selector:
proxy.open-cluster-management.io/component-name: proxy-server
ports:
- name: agent-server
port: 8091
targetPort: 8091
nodePort: 30091
protocol: TCP
EOF
Verifying the Deployment
After completing the installation, verify that the cluster-proxy-addon-user deployment and service have been created and are running in the open-cluster-management-addon namespace:
kubectl get deploy -n open-cluster-management-addon
NAME READY UP-TO-DATE AVAILABLE AGE
cluster-proxy-addon-user 1/1 1 1 10s
kubectl get svc -n open-cluster-management-addon
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cluster-proxy-addon-user ClusterIP 10.96.100.100 <none> 443/TCP 10s
Using Service Proxy to Access Managed Clusters
Now that the installation is complete, let’s demonstrate how to use the Service Proxy feature to access resources in managed clusters. We’ll access pods in the open-cluster-management-agent namespace in the managed cluster, which will also showcase the impersonation authentication mechanism.
Creating a Hub User
First, create a hub user (a service account in the hub cluster) named test-sa:
kubectl --context kind-hub create serviceaccount -n open-cluster-management-hub test-sa
Configuring RBAC Permissions
Next, create a Role and RoleBinding in the managed cluster to grant the test-sa user permission to list and get pods in the open-cluster-management-agent namespace:
kubectl --context kind-managed apply -f - <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: test-sa-rolebinding
namespace: open-cluster-management-agent
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: test-sa-role
subjects:
- kind: User
name: cluster:hub:system:serviceaccount:open-cluster-management-hub:test-sa
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: test-sa-role
namespace: open-cluster-management-agent
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list"]
EOF
Important Note:
- The
Username follows the formatcluster:hub:system:serviceaccount:<namespace>:<serviceaccount>, where<namespace>and<serviceaccount>are the namespace and name of the service account in the hub cluster. - Alternatively, you can use cluster-permission to create roles and role bindings from the hub cluster side.
Generating an Access Token
Generate a token for the test-sa service account:
TOKEN=$(kubectl --context kind-hub -n open-cluster-management-hub create token test-sa)
Testing the Service Proxy
Now let’s test accessing pods in the managed cluster through the cluster-proxy-addon-user service. We’ll start a debug container in the hub cluster and use curl to make the request:
POD=$(kubectl get pods -n open-cluster-management-addon -l component=cluster-proxy-addon-user --field-selector=status.phase=Running -o jsonpath='{.items[0].metadata.name}')
kubectl debug -it $POD -n open-cluster-management-addon --image=praqma/network-multitool -- sh -c "curl -k -H 'Authorization: Bearer $TOKEN' https://cluster-proxy-addon-user.open-cluster-management-addon.svc.cluster.local:9092/managed/api/v1/namespaces/open-cluster-management-agent/pods"
The URL structure for accessing resources is:
https://cluster-proxy-addon-user.<namespace>.svc.cluster.local:9092/<cluster-name>/<kubernetes-api-path>
You should see a JSON response listing the pods in the open-cluster-management-agent namespace of the managed cluster, demonstrating successful authentication and authorization through the impersonation mechanism.
Summary
In this blog post, we’ve demonstrated the new Service Proxy feature introduced in cluster-proxy v0.9.0. The key highlights include:
- Service Proxy: A new HTTPS-based method to access services in managed clusters without requiring the konnectivity client package
- Impersonation: A user-friendly authentication mechanism that allows hub users to access managed cluster resources using their hub tokens
- Simple URL Structure: Access managed cluster resources through a straightforward URL pattern
These features significantly simplify the process of accessing managed cluster services, making it easier to build tools and integrations on top of OCM’s multi-cluster management capabilities.
We hope you find these new features useful! For more information, please visit the cluster-proxy GitHub repository.
Open Cluster Management 社区诚邀您共赴 KubeCon China 2025 探讨多集群管理新未来
KubeCon + CloudNativeCon China 2025 即将于6 月 10-11 日在香港盛大举行,这是云原生领域最具影响力的技术盛会之一。作为云原生多集群管理领域的领军项目之一,Open Cluster Management (OCM) 社区将带来三个精彩议题,与您共同探讨多集群管理领域的最新创新和突破。在这里,您将有机会与来自全球的云原生专家面对面交流,深入了解 OCM 如何通过创新的技术方案,帮助企业应对日益复杂的多集群管理挑战,开启云原生多集群管理的新篇章。

议题信息
闪电演讲:使用OCM Addon简化多集群集成
时间:6 月 10 日 11:42 - 11:47 HKT
地点:Level 16 | Grand Ballroom I
演讲者:Jian Zhu (Red Hat)
在这个闪电演讲中,Jian Zhu 将介绍 OCM 的 Addon 机制,展示如何通过简单的 YAML 文件实现多集群能力的扩展。主要内容包括:
- OCM Addon 机制概述及其在多集群环境中的作用
- 项目集成案例:以 Fluid 为例,展示如何通过 Addon 增强多集群管理能力
- AddonTemplate API:简化 addon 创建和管理的创新方案
- 实际应用价值:展示 OCM Addons 的效率和可扩展性
解锁 CEL 在多集群调度中的强大能力
时间:6 月 10 日 17:00 - 17:30 HKT
地点:Level 19 | Crystal Court II
演讲者:Qing Hao (Red Hat)
Common Expression Language (CEL) 作为 Kubernetes API 中的强大工具,在 Kubernetes v1.32 中被用于变异准入策略,同时也在 Envoy 和 Istio 中得到广泛应用。本次演讲将深入探讨 CEL 在多集群调度中带来的优势和特性。
随着多集群调度需求的不断增长,用户对调度策略的精细化和定制化要求越来越高。例如,用户可能希望使用 “version” > v1.30.0 这样的标签表达式来筛选集群,而不是简单地列出所有版本。许多用户还希望能够使用自定义资源(CRD)字段或指标来进行调度决策。CEL 的扩展性能够有效应对这些挑战,因为它可以处理复杂的表达式。
在本次演讲中,我们将展示 Open Cluster Management (OCM) 如何利用 CEL 实现多集群调度。以 ClusterProfile API 为例,我们将演示 CEL 如何满足复杂的调度需求,并通过解决装箱(bin-packing)问题来展示其在提升 AI 应用 GPU 资源利用率方面的潜力。
统一混合多集群认证体验:SPIFFE 与 Cluster Inventory API 的结合
时间:6 月 11 日 13:45 - 14:15 HKT
地点:Level 16 | Grand Ballroom I
演讲者:Chen Yu (Microsoft) & Jian Zhu (Red Hat)
随着多集群模式的不断发展,为团队和多集群应用(如 Argo 和 Kueue)管理 Kubernetes 身份、凭证和权限变得越来越繁琐。目前的做法通常需要在每个集群上单独管理服务账号,并在集群间传递凭证。这种设置往往分散、重复,难以追踪和审计,还可能带来安全和运维方面的挑战。在混合云环境中,由于不同平台可能采用不同的解决方案,这个问题尤为突出。
本次演示将介绍一个基于 OpenID、SPIFFE/SPIRE 和 Multi-Cluster SIG 的 Cluster Inventory API 的解决方案,它能够提供统一、无缝且安全的认证体验。通过 CNCF 多集群项目 OCM 和 Kueue 的支持,与会者将了解如何利用开源解决方案来消除凭证分散问题,降低运维复杂度,并在混合云环境中为团队和应用访问多集群设置时提升安全性。
演讲者信息
Jian Zhu
职位:高级软件工程师,Red Hat
简介:Jian Zhu 是 Red Hat 的高级软件工程师,KubeCon China 2024 的演讲嘉宾,也是 Open Cluster Management 项目的核心贡献者。他专注于解决多集群工作负载分发问题和通过 addon 机制扩展 OCM 的功能。
Qing Hao
职位:高级软件工程师,Red Hat
简介:Qing Hao 是 Red Hat 的高级软件工程师,担任 Open Cluster Management 的维护者。她同时担任 CNCF Ambassador,是 KubeCon China 2024 的演讲嘉宾,以及 OSPP 2022 和 GSoC 2024 的导师。她专注于解决多集群环境中的复杂挑战,例如应用调度和管理组件的滚动升级。在加入 Red Hat 之前,Qing 曾在 IBM 工作,在容器、云原生技术和高性能计算(HPC)领域拥有多年经验。
展台信息
除了精彩的演讲,Open Cluster Management 还将在 KubeCon China 2025 设置展台,欢迎您前来交流!
展台信息:
- 项目:Open Cluster Management
- 展台编号:8
- 展台位置:Hopewell Hotel | Level 16 | Grand Ballroom II | Solutions Showcase
- 展台时间:6 月 11 日 10:15 - 12:30 HKT
在展台,您将有机会:
- 与 OCM 核心开发者面对面交流
- 了解最新的多集群管理解决方案
- 探讨实际应用场景和技术挑战
- 获取社区资源和参与方式以及一些精美的小礼品

加入我们
Open Cluster Management 社区诚挚邀请您参加这些精彩演讲,一起探讨多集群管理的未来发展方向。无论您是开发者、运维工程师还是架构师,都能在这些议题中找到有价值的内容。
让我们相约 KubeCon China 2025,共同探讨云原生多集群管理的创新与实践!
相关资源
Joining OCM Hub and Spoke using AWS IRSA authentication
Refer this solution.
KubeCon NA 2024 - Scheduling AI Workload Among Multiple Clusters
Read more at KubeCon NA 2024 - Open Cluster Management: Scheduling AI Workload Among Multiple Clusters | Project Lightning Talk | video.
KubeDay Australia 2024 - Open Sourcing the Open Cluster Management Project and the Lessons We Can Learn for AI
Read more at KubeDay Australia 2024 - Open Sourcing the Open Cluster Management Project and the Lessons We Can Learn for AI | video.
KubeCon CN 2024 - Boundaryless Computing: Optimizing LLM Performance, Cost, and Efficiency in Multi-Cloud Architecture | 无边界计算:在多云架构中优化LLM性能、成本和效率
Read more at KubeCon CN 2024 - Boundaryless Computing: Optimizing LLM Performance, Cost, and Efficiency in Multi-Cloud Architecture.
KubeCon CN 2024 - Connecting the Dots: Towards a Unified Multi-Cluster AI/ML Experience | 连接点:走向统一的多集群AI/ML体验
Read more at KubeCon CN 2024 - Connecting the Dots: Towards a Unified Multi-Cluster AI/ML Experience.
KubeCon CN 2024 - Extend Kubernetes to Edge Using Event-Based Transport | 使用基于事件的传输将Kubernetes扩展到边缘
Read more at KubeCon CN 2024 - Extend Kubernetes to Edge Using Event-Based Transport.
The HA Hub clusters solution -- MultipleHubs
The MultipleHubs is a new feature in Open Cluster Management (OCM) that allows you to configure a list of bootstrap kubeconfigs of multiple hubs. This feature is designed to provide a high availability (HA) solution of hub clusters. In this blog, we will introduce the MultipleHubs feature and how to use it.
The high availability of hub clusters means that if one hub cluster is down, the managed clusters can still communicate with other hub clusters. Users can also specify the hub cluster that the managed cluster should connect to by configuring the ManagedCluster resource.
The MultipleHubs feature is currently in the experimental stage and is disabled by default. To enable the MultipleHubs feature, you need to set the featureGate in Klusterlet’s registration configuration. The following is an example of the Klusterlet’s registration configuration:
apiVersion: operator.open-cluster-management.io/v1
kind: Klusterlet
...
spec:
...
registrationConfiguration:
...
featureGates:
- feature: MultipleHubs
mode: Enable
If MultipleHubs is enabled, you don’t need to prepare the default bootstrapKubeConfig for the managed cluster. The managed cluster will use the bootstrapKubeConfigs in the Klusterlet’s registration configuration to connect to the hub clusters. An example of bootstrapKubeConfigs is like following:
apiVersion: operator.open-cluster-management.io/v1
kind: Klusterlet
...
spec:
...
registrationConfiguration:
...
featureGates:
- feature: MultipleHubs
mode: Enable
bootstrapKubeConfigs:
type: "LocalSecrets"
localSecretsConfig:
kubeConfigSecrets:
- name: "hub1-bootstrap"
- name: "hub2-bootstrap"
hubConnectionTimeoutSeconds: 600
In the above configuration, the hub1-bootstrap and hub2-bootstrap are the secrets that contain the kubeconfig of the hub clusters. You should create the secrets before you set the bootstrapKubeConfigs in the Klusterlet’s registration configuration.
The order of the secrets in the kubeConfigSecrets is the order of the hub clusters that the managed cluster will try to connect to. The managed cluster will try to connect to the first hub cluster in the list first. If the managed cluster cannot connect to the first hub cluster, it will try to connect to the second hub cluster, and so on.
Note that the expiration time of the credentials in kubeconfigs should be long enough to ensure the managed cluster can connect to another hub cluster when one hub cluster is down.
The hubConnectionTimeoutSeconds is the timeout for the managed cluster to connect to the hub clusters. If the managed cluster cannot connect to the hub cluster within the timeout, it will try to connect to another hub cluster. It is also used to avoid the effect of network disturbance. The default value is 600 seconds and the minimum value is 180 seconds.
Currently, the MultipleHubs feature only supports the LocalSecrets type of bootstrapKubeConfigs.
As we mentioned before, you can also specify the hub’s connectivity in the ManagedCluster resource from the hub side. We use the hubAcceptsClient field in the ManagedCluster resource to specify whether the hub cluster accepts the managed cluster. The following is an example of the ManagedCluster resource:
apiVersion: cluster.open-cluster-management.io/v1
kind: ManagedCluster
...
spec:
...
hubAcceptsClient: false
If the hubAcceptsClient is set to false, the managed cluster currently connected to the hub will immediately disconnect from the hub and try to connect to another hub cluster.
And the managed clusters that are trying to connect to another hub cluster will ignore the hub cluster that the managed cluster’s hubAcceptsClient is set to false.
That’s the brief introduction of the MultipleHubs feature in Open Cluster Management. We hope this feature can help you to start building a high availability solution of hub clusters and we are looking forward to your feedback. If you have any questions or suggestions, please feel free to contact us.
Using the GitOps way to deal with the upgrade challenges of multi-cluster tool chains
Upgrading challenges of tool chains in multi-cluster environments
Open Cluster Management (OCM) is a community-driven project focused on multicluster and multicloud scenarios for Kubernetes applications. It provides functions such as cluster registration, application and workload distribution, and scheduling. Add-on is an extension mechanism based on the foundation components provided by OCM, which allows applications in the Kubernetes ecosystem to be easily migrated to the OCM platform and has the ability to orchestrate and schedule across multiple clusters and multiple clouds. For example, Istio, Prometheus, and Submarine can be expanded to multiple clusters through Add-on. In a multi-cluster environment, how to upgrade the entire tool chain (such as Istio, Prometheus and other tools) gracefully and smoothly is a challenge we encounter in multi-cluster management. A failed upgrade of the tool chain can potentially render thousands of user workloads inaccessible. Therefore, finding an easy and safe upgrade solution across clusters becomes important.
In this article, we will introduce how Open Cluster Management (OCM) treats tool chain upgrades as configuration file changes, allowing users to leverage Kustomize or GitOps to achieve seamless rolling/canary upgrades across clusters.
Before we begin, let us first introduce several concepts in OCM.
Add-on
On the OCM platform, add-on can apply different configurations on different managed clusters, and can also implement functions such as obtaining data from the control plane (Hub) to the managed cluster. For example, you can use managed-serviceaccount, this add-on returns the specified ServiceAccount information on the managed cluster to the hub cluster. You can use the cluster-proxy add-on to establish a reverse proxy channel from spoke to hub.
At this stage, there are some add-ons in the OCM community:
- Multicluster Mesh Addon can be used to manage (discovery, deploy and federate) service meshes across multiple clusters in OCM.
- Submarine Addon deploys the Submariner Broker on the Hub cluster and the required Submariner components on the managed clusters.
- Open-telemetry add-on automates the installation of otelCollector on both hub cluster and managed clusters and jaeget-all-in-one on hub cluster for processing and storing the traces.
- Application lifecycle management enables application lifecycle management in multi-cluster or multi-cloud environments.
- Policy framework and Policy controllers allows Hub cluster administrators to easily deploy security-related policies for managed clusters.
- Managed service account enables a hub cluster admin to manage service account across multiple clusters on ease.
- Cluster proxy provides L4 network connectivity from hub cluster to the managed clusters.
For more information about add-on, please refer to Add-on concept and Add-on Developer Guide.
OCM provides two ways to help developers develop their own add-ons:
- Hard mode: Using the built-in mechanism of addon-framework, you can follow the Add-on Development Guide to develop the addon manager and addon agent.
- Easy mode: OCM provides a new development model, which can use AddOnTemplate to build add-on. In this model, developers do not need to develop the addon manager, but only need to prepare the addon agent’s image and
AddOnTemplate.AddOnTemplatedescribes how to deploy the addon agent and how to register the add-on.
Below is the ClusterManagementAddOn and AddOnTemplate of a sample add-on. AddOnTemplate is treated as an add-on configuration file, defined in supportedConfigs. The AddOnTemplate resource contains the manifest required to deploy the add-on and the add-on registration method.
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: hello-template
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
addOnMeta:
description: hello-template is an addon built with addon template
displayName: hello-template
supportedConfigs: # declare it is a template type addon
- group: addon.open-cluster-management.io
resource: addontemplates
defaultConfig:
name: hello-template
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: AddOnTemplate
metadata:
name: hello-template
spec:
addonName: hello-template
agentSpec: #required
workload:
manifests:
- kind: Deployment
metadata:
name: hello-template-agent
namespace: open-cluster-management-agent-addon
...
- kind: ServiceAccount
metadata:
name: hello-template-agent-sa
namespace: open-cluster-management-agent-addon
- kind: ClusterRoleBinding
metadata:
name: hello-template-agent
...
registration: #optional
...
Placement Decision Strategy
The Placement API is used to select a set of ManagedClusters in one or more ManagedClusterSets to deploy workloads to these clusters.
For more introduction to the Placement API, please refer to Placement concept.
The “input” and “output” of the Placement scheduling process are decoupled into two independent Kubernetes APIs: Placement and PlacementDecision.
- Placement provides filtering of clusters through the
labelSelectoror theclaimSelector, and also provides some built-inprioritizers, which can score, sort and prioritize the filtered clusters. - The scheduling results of
Placementwill be placed inPlacementDecision,status.decisionslists the top N clusters with the highest scores and sorts them by name, and the scheduling results will dynamically change as the cluster changes. ThedecisionStrategysection in Placement can be used to divide the createdPlacementDecisioninto multiple groups and define the number of clusters in each decision group.PlacementDecisionsupports paging display, and each resource supports containing 100 cluster names.
Below is an example of Placement and decisionStrategy. Assume that there are 300 ManagedClusters in the global ManagedClusterSets, and 10 of them have the label canary. The following example describes grouping the canary-labeled clusters into a group and grouping the remaining clusters into groups of up to 150 clusters each.
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: Placement
metadata:
name: aws-placement
namespace: default
spec:
clusterSets:
- global
decisionStrategy:
groupStrategy:
clustersPerDecisionGroup: 150
decisionGroups:
- groupName: canary
groupClusterSelector:
labelSelector:
matchExpressions:
- key: canary
operator: Exists
The grouped results will be displayed in the status of Placement. The canary group has 10 clusters, and the results are placed in aws-placement-decision-1. The other default groupings are only group index, each group has 150 and 140 clusters respectively. Since a PlacementDecsion only supports 100 clusters, the results for each group are put into two PlacementDecisions.
status:
...
decisionGroups:
- clusterCount: 10
decisionGroupIndex: 0
decisionGroupName: canary
decisions:
- aws-placement-decision-1
- clusterCount: 150
decisionGroupIndex: 1
decisionGroupName: ""
decisions:
- aws-placement-decision-2
- aws-placement-decision-3
- clusterCount: 140
decisionGroupIndex: 2
decisionGroupName: ""
decisions:
- placement1-decision-3
- placement1-decision-4
numberOfSelectedClusters: 300
Taking the canary group as an example, its PlacementDecision is as follows, where the label cluster.open-cluster-management.io/decision-group-index represents the index of the group to which it belongs, cluster.open-cluster-management.io/decision-group-name represents the name of the group it belongs to, and cluster.open-cluster-management.io/placement represents the Placement it belongs to. Users can flexibly obtain scheduling results through tag selectors.
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: PlacementDecision
metadata:
labels:
cluster.open-cluster-management.io/decision-group-index: "0"
cluster.open-cluster-management.io/decision-group-name: canary
cluster.open-cluster-management.io/placement: aws-placement
name: aws-placement-decision-1
namespace: default
status:
decisions:
- clusterName: cluster1
reason: ""
...
- clusterName: cluster10
reason: ""
Simplify upgrades the GitOps way
The above briefly introduces the concepts of add-on template and placement decision strategy.
In OCM, we regard the upgrade of add-on as the upgrade of its configuration file. The configuration here can be AddOnTemplate or other customized configuration file such as AddOnDeploymentConfig. An add-on upgrade is treated as a configuration file update, which enables users to leverage Kustomize or GitOps for seamless cross-cluster rolling/canary upgrades. RolloutStrategy defines the upgrade strategy, supports upgrade all, progressive upgrades by cluster and progressive upgrades by cluster group, and can define a set of MandatoryDecisionGroups to try new configurations first.
According to the four principles of GitOps, let’s take a look at how OCM supports the GitOps approach to address upgrade challenges in multi-cluster environments.
- Declarative
The configuration file used by add-on can be declared in ClusterManagementAddOn. The configuration file can be declared in the global supportedConfigs, and the configuration file will be applied to all ManagedClusterAddOn instances. It can also be declared in different placements under installStrategy. The ManagedClusterAddOn of the cluster selected by each Placement will have the same configuration file. The configuration declared in placements will override the global configuration.
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
spec:
supportedConfigs:
- defaultConfig:
name: managed-serviceaccount-0.4.0
group: addon.open-cluster-management.io
resource: addontemplates
installStrategy:
placements:
- name: aws-placement
namespace: default
configs:
- group: addon.open-cluster-management.io
resource: addondeploymentconfigs
name: managed-serviceaccount-addon-deploy-config
rolloutStrategy:
type: Progressive
progressive:
mandatoryDecisionGroups:
- groupName: "canary"
maxConcurrency: 1
type: Placements
- Version control
Changes in the add-on configuration file name or spec content will be considered a configuration change and will trigger an upgrade of the add-on. Users can leverage Kustomize or GitOps to control configuration file upgrades.
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: AddOnTemplate
metadata:
name: managed-serviceaccount-0.4.0
spec:
agentSpec: # required
workload:
manifests:
- kind: Deployment
metadata:
name: managed-serviceaccount-addon-agent
namespace: open-cluster-management-agent-addon
...
- kind: ServiceAccount
metadata:
name: managed-serviceaccount
namespace: open-cluster-management-agent-addon
…
registration: # optional
- Automation
The OCM component addon-manager-controller under the open-cluster-management-hub namespace is a more general addon manager. It will watch the following two types of add-on and be responsible for maintaining the lifecycle of such add-on. Includes installation and upgrades. When the name or spec content of the configuration file changes, this component will upgrade the add-on according to the upgrade strategy defined by rolloutStrategy.
- Hard mode: Using the add-on developed by the latest addon-framework, you need to delete the
WithInstallStrategy()method in the code and add annotationaddon.open-cluster-management.io/lifecycle: "addon-manager"inClusterManagementAddOn. For details, refer to Add-on Development Guide. - Easy mode: add-on developed using
AddOnTemplatemode.
✗ kubectl get deploy -n open-cluster-management-hub
NAME READY UP-TO-DATE AVAILABLE AGE
cluster-manager-addon-manager-controller 1/1 1 1 10h
cluster-manager-placement-controller 1/1 1 1 10h
cluster-manager-registration-controller 1/1 1 1 10h
cluster-manager-registration-webhook 1/1 1 1 10h
cluster-manager-work-webhook 1/1 1 1 10h
- Coordination
The spec hash of the add-on configuration file will be recorded in the status of ClusterManagementAddOn and ManagedClusterAddOn. When the spec hash changes, add-on-manager-controller will continue to update the add-on according to the upgrade strategy defined by rolloutStrategy until lastAppliedConfig, lastKnownGoodConfig is consistent with desiredConfig. In the following example, because lastAppliedConfig does not match desiredConfig, the add-on status is displayed as “Upgrading”.
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
…
status:
installProgressions:
- conditions:
- lastTransitionTime: "2023-09-21T06:53:59Z"
message: 1/3 upgrading, 0 timeout.
reason: Upgrading
status: "False"
type: Progressing
configReferences:
- desiredConfig:
name: managed-serviceaccount-0.4.1
specHash: dcf88f5b11bd191ed2f886675f967684da8b5bcbe6902458f672277d469e2044
group: addon.open-cluster-management.io
lastAppliedConfig:
name: managed-serviceaccount-0.4.0
specHash: 1f7874ac272f3e4266f89a250d8a76f0ac1c6a4d63d18e7dcbad9068523cf187
lastKnownGoodConfig:
name: managed-serviceaccount-0.4.0
specHash: 1f7874ac272f3e4266f89a250d8a76f0ac1c6a4d63d18e7dcbad9068523cf187
resource: addontemplates
name: aws-placementl
namespace: default
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ManagedClusterAddOn
metadata:
name: managed-serviceaccount
namespace: cluster1
…
status:
conditions:
- lastTransitionTime: "2023-09-21T06:53:42Z"
message: upgrading.
reason: Upgrading
status: "False"
type: Progressing
configReferences:
- desiredConfig:
name: managed-serviceaccount-0.4.1
specHash: dcf88f5b11bd191ed2f886675f967684da8b5bcbe6902458f672277d469e2044
group: addon.open-cluster-management.io
lastAppliedConfig:
name: managed-serviceaccount-0.4.0
specHash: dcf88f5b11bd191ed2f886675f967684da8b5bcbe6902458f672277d469e2044
lastObservedGeneration: 1
name: managed-serviceaccount-0.4.1
resource: addontemplates
Three upgrade strategies
The rolloutStrategy field of ClusterManagementAddOn defines the upgrade strategy. Currently, OCM supports three types of upgrade strategies.
- All
The default upgrade type is All, which means the new configuration file will be applied to all the clusters immediately.
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
supportedConfigs:
...
installStrategy:
placements:
- name: aws-placement
namespace:default
rolloutStrategy:
type: All
type: Placement
- Progressive
Progressive means that the new configuration file will be deployed to the selected clusters progressively per cluster. The new configuration file will not be applied to the next cluster unless one of the current applied clusters reach the successful state and haven’t breached the MaxFailures. We introduced the concept of “Placement Decision Group” earlier. One or more decision groups can be specified in MandatoryDecisionGroups. If MandatoryDecisionGroups are defined, new configuration files are deployed to these cluster groups first. MaxConcurrency defines the maximum number of clusters deployed simultaneously.
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
supportedConfigs:
...
installStrategy:
placements:
- name: aws-placement
namespace:default
rolloutStrategy:
type: Progressive
progressive:
mandatoryDecisionGroups:
- groupName: "canary"
maxConcurrency: 1
type: Placements
- ProgressivePerGroup
ProgressivePerGroup means that the new configuration file will be deployed to decisionGroup clusters progressively per group. The new configuration file will not be applied to the next cluster group unless all the clusters in the current group reach the successful state and haven’t breached the MaxFailures. If MandatoryDecisionGroups are defined, new configuration files are deployed to these cluster groups first. If there are no MandatoryDecisionGroups, the cluster group will be upgraded in order of index.
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
supportedConfigs:
...
installStrategy:
placements:
- name: aws-placement
namespace:default
rolloutStrategy:
type: ProgressivePerGroup
progressivePerGroup:
mandatoryDecisionGroups:
- groupName: "canary"
type: Placements
According to the four principles of GitOps and the three upgrade strategies of OCM, users can use Kustomize or GitOps to achieve seamless rolling/canary upgrades across clusters. It is worth noting that installStrategy supports multiple placement definitions, and users can implement more advanced upgrade strategies based on this.
As in the example below, you can define two placements at the same time to select clusters on aws and gcp respectively, so that the same add-on can use different configuration files and upgrade strategies in different clusters.
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
supportedConfigs:
...
installStrategy:
placements:
- name: aws-placement
namespace: default
configs:
- group: addon.open-cluster-management.io
resource: addondeploymentconfigs
name: managed-serviceaccount-addon-deploy-config-aws
rolloutStrategy:
type: ProgressivePerGroup
progressivePerGroup:
mandatoryDecisionGroups:
- groupName: "canary"
type: Placements
- name: gcp-placement
namespace: default
configs:
- group: addon.open-cluster-management.io
resource: addondeploymentconfigs
name: managed-serviceaccount-addon-deploy-config-gcp
rolloutStrategy:
type: ProgressivePerGroup
progressivePerGroup:
mandatoryDecisionGroups:
- groupName: "canary"
type: Placements
Three upgrade configurations
The rolloutStrategy upgrade strategy can also define MinSuccessTime, ProgressDeadline and MaxFailures to achieve more fine-grained upgrade configuration.
- MinSuccessTime
MinSuccessTime defines how long the controller needs to wait before continuing to upgrade the next cluster when the addon upgrade is successful and MaxFailures is not reached. The default value is 0 meaning the controller proceeds immediately after a successful state is reached.
In the following example, add-on will be upgraded at a rate of one cluster every 5 minutes.
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
supportedConfigs:
...
installStrategy:
placements:
- name: aws-placement
namespace: default
rolloutStrategy:
type: Progressive
progressive:
mandatoryDecisionGroups:
- groupName: "canary"
maxConcurrency: 1
minSuccessTime: "5m"
type: Placements
- ProgressDeadline
ProgressDeadline defines the maximum time for the controller to wait for the add-on upgrade to be successful. If the add-on does not reach a successful state after ProgressDeadline, controller will stop waiting and this cluster will be treated as “timeout” and be counted into MaxFailures. Once the MaxFailures is breached, the rollout will stop. The default value is “None”, which means the controller will wait for a successful state indefinitely.
In the following example, the controller will wait for 10 minutes on each cluster until the addon upgrade is successful. If it fails after 10 minutes, the upgrade status of the cluster will be marked as “timeout”.
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
supportedConfigs:
...
installStrategy:
placements:
- name: aws-placement
namespace:default
rolloutStrategy:
type: Progressive
progressive:
mandatoryDecisionGroups:
- groupName: "canary"
maxConcurrency: 1
progressDeadline: "10m"
type: Placements
- MaxFailures
MaxFailures defines the number of clusters that can tolerate upgrade failures, which can be a numerical value or a percentage. If the cluster status is failed or timeout, it will be regarded as an upgrade failure. If the failed cluster exceeds MaxFailures, the upgrade will stop.
In the following example, when 3 addons fail to upgrade or does not reach successful status for more than 10 minutes, the upgrade will stop.
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
supportedConfigs:
...
installStrategy:
placements:
- name: aws-placement
namespace: default
rolloutStrategy:
type: Progressive
progressive:
mandatoryDecisionGroups:
- groupName: "canary"
maxConcurrency: 1
maxFailures: 2
progressDeadline: "10m"
type: Placements
Summary
This article details how to use Open Cluster Management to address tool chain upgrade challenges in a multi-cluster environment using the GitOps way. OCM provides a Kubernetes-based management platform across multiple clusters and multiple clouds. Through Add-on and Placement API, users can upgrade the entire tool chain gracefully and smoothly. At the same time, OCM treats add-on upgrades as configuration file changes, enabling users to leverage Kustomize or GitOps for seamless rolling/canary upgrades across clusters. In addition, OCM also provides a variety of upgrade strategies, including all upgrade (All), progressive upgrade by cluster (Progressive) and progressive upgrade by cluster group (ProgressivePerGroup) to meet different upgrade needs.
Open Cluster Management - Configuring Your Kubernetes Fleet With the Policy Addon
View the video at YouTube.
以GitOps方式应对多集群工具链的升级挑战
多集群环境下工具链的升级挑战
OCM(open-cluster-management)是一个专注于 Kubernetes 应用跨多集群和多云的管理平台,提供了集群的注册,应用和负载的分发,调度等基础功能。Add-on 插件是 OCM 提供的一种基于基础组件的扩展机制,可以让 Kubernetes 生态的应用很容易迁移到 OCM 平台上,拥有跨多集群多云的编排和调度的能力。如 Istio,Prometheus,Submarine 可以通过 Add-on 的方式扩展至多集群。在多集群环境中,如何优雅、平滑地升级整个工具链(比如 Istio、Prometheus 和其他工具)是我们在多集群管理中遇到的挑战,工具链的升级失败可能会导致数千个用户工作负载无法访问。因此,找到一种简单、安全的跨集群升级解决方案变得非常重要。
本文我们将介绍 Open Cluster Management(OCM)如何将工具链升级视为配置文件的变更,使用户能够利用 Kustomize 或 GitOps 实现跨集群的无缝滚动/金丝雀升级。
在正式开始前,首先介绍几个 OCM 中的概念。
add-on 插件
在 OCM 平台上,add-on 插件可以实现在不同托管集群(Spoke)上应用不同的配置,也可以实现从控制面(Hub)获取数据到 Spoke 集群上等功能。比如:你可以使用managed-serviceaccount 插件在 Spoke 集群上将指定的 ServiceaCount 信息返回给 Hub 集群,可以使用cluster-proxy插件建立一个从 spoke 到 hub 的反向代理通道。
现阶段 OCM 社区已经有的一些 add-on:
- Multicluster Mesh Addon 可用于管理(发现、部署和联合)OCM 中跨多个集群的服务网格。
- Submarine Addon 让Submarine 和 OCM 方便集成,在 hub cluster 上部署 Submariner Broker,在 managed cluster 上部署所需的 Submariner 组件, 为托管集群提供跨集群的 Pod 和 Service 网络互相访问的能力。
- Open-telemetry add-on 自动在 hub cluster 和 managed cluster 上 安装 otelCollector,并在 hub cluster 上自动安装 jaeger-all-in-one 以处理和存储 traces。
- Application lifecycle management 实现多集群或多云环境中的应用程序生命周期管理。add-on 插件提供了一套通过 Subscriptions 订阅 channel,将 github 仓库,Helm release 或者对象存储仓库的应用分发到指定 Spoke 集群上的机制。
- Policy framework和Policy controllers add-on 插件可以让 Hub 集群管理员很轻松为 Spoke 集群部署安全相关的 policy 策略。
- Managed service account add-on 插件可以让 Hub 集群管理员很容易管理 Spoke 集群上 serviceaccount。
- Cluster proxy add-on 插件通过反向代理通道提供了 Hub 和 Spoke 集群之间 L4 网络连接。
更多关于 add-on 插件的介绍可以参考详解 OCM add-on 插件。
OCM 提供了两种方式帮助开发者开发自己的 add-on:
- Hard 模式:使用addon-framework的内置机制,可根据Add-on 开发指南来开发 add-on 插件的 addon manager 和 addon agent。
- Easy 模式:OCM 提供了一个新的插件开发模型,可使用AddOnTemplate来构建 add-on。在此模型中开发者无需开发 addon manager,只需准备 addon agent 的 image 和 AddOnTemplate,AddOnTemplate 描述了如何部署 addon agent 以及如何注册 addon。
如下是一个样例 add-on 的 ClusterManagementAddOn 和 AddOnTemplate。AddOnTemplate 被视为 add-on 一个配置文件,定义在 supportedConfigs 中。AddOnTemplate 资源中则包含了部署 add-on 所需的 manifest 以及 add-on 的注册方式。
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: hello-template
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
addOnMeta:
description: hello-template is a addon built with addon template
displayName: hello-template
supportedConfigs: # declare it is a template type addon
- group: addon.open-cluster-management.io
resource: addontemplates
defaultConfig:
name: hello-template
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: AddOnTemplate
metadata:
name: hello-template
spec:
addonName: hello-template
agentSpec: # required
workload:
manifests:
- kind: Deployment
metadata:
name: hello-template-agent
namespace: open-cluster-management-agent-addon
...
- kind: ServiceAccount
metadata:
name: hello-template-agent-sa
namespace: open-cluster-management-agent-addon
- kind: ClusterRoleBinding
metadata:
name: hello-template-agent
...
registration: # optional
...
Placement Decision Strategy
Placement API 用于在一个或多个托管集群组(ManagedClusterSet)中选择一组托管群集(ManagedCluster),以便将工作负载部署到这些群集上。
更多关于 Placement API 的介绍可以参考Placement 文档。
Placement 调度过程的“输入”和“输出”被解耦为两个独立的 Kubernetes API: Placement 和 PlacementDecision。
- Placement 提供了通过标签选择器
labelSelector或声明选择器claimSelector过滤集群,同时也提供了一些内置的优选器prioritizer,可对过滤后的集群进行打分排序和优先选择。 - Placement 的调度结果会放在
PlacementDecision中,status.decisions列出得分最高的前 N 个集群并按名称排序,且调度结果会随着集群的变化而动态变化。Placement 中的decisionStrategy部分可以用来将创建的PlacementDecision划分为多个组,并定义每个决策组中的集群数量。PlacementDecision支持分页显示,每个 resource 做多支持放置 100 个集群的名称。
如下是一个 Placement 和decisionStrategy的例子。假设 global 集群组中有 300 个托管集群(ManagedCluster),其中 10 个集群有标签 canary。下面的例子描述了将拥有 canary 标签的集群分为一组,并将剩下的集群以每组最多 150 个集群来进行分组。
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: Placement
metadata:
name: aws-placement
namespace: default
spec:
clusterSets:
- global
decisionStrategy:
groupStrategy:
clustersPerDecisionGroup: 150
decisionGroups:
- groupName: canary
groupClusterSelector:
labelSelector:
matchExpressions:
- key: canary
operator: Exists
分组的结果将显示在 Placement 的 status 中。其中 canary 组有 10 个集群,结果放在 aws-placement-decision-1 中。其他的默认分组只有 group index,每组分别有 150 个和 140 个集群。由于一个 PlacementDecsion 只支持 100 个集群,因此每组的结果放入两个 PlacementDecision 中。
status:
...
decisionGroups:
- clusterCount: 10
decisionGroupIndex: 0
decisionGroupName: canary
decisions:
- aws-placement-decision-1
- clusterCount: 150
decisionGroupIndex: 1
decisionGroupName: ""
decisions:
- aws-placement-decision-2
- aws-placement-decision-3
- clusterCount: 140
decisionGroupIndex: 2
decisionGroupName: ""
decisions:
- placement1-decision-3
- placement1-decision-4
numberOfSelectedClusters: 300
以 canary 组为例,它的 PlacementDecision 如下所示,其中的标签 cluster.open-cluster-management.io/decision-group-index 代表了所属组的 index,cluster.open-cluster-management.io/decision-group-name 代表了所属组的名称,cluster.open-cluster-management.io/placement 代表了所属于的 Placement。使用者可以通过标签选择器来灵活获取调度结果。
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: PlacementDecision
metadata:
labels:
cluster.open-cluster-management.io/decision-group-index: "0"
cluster.open-cluster-management.io/decision-group-name: canary
cluster.open-cluster-management.io/placement: aws-placement
name: aws-placement-decision-1
namespace: default
status:
decisions:
- clusterName: cluster1
reason: ""
...
- clusterName: cluster10
reason: ""
以 GitOps 方式简化升级
以上简单介绍了 add-on template 和 placement decision strategy 的概念。
在 OCM 中,我们将 add-on 的升级视为其配置文件的升级,这里的配置可以是 AddOnTemplate,也可以是其他自定义的配置文件 AddOnDeploymentConfig。一次 add-on 的升级等同于一次配置文件的更新,这使得用户能够利用 Kustomize 或 GitOps 来进行无缝的跨集群滚动/金丝雀升级。RolloutStrategy 定义了升级策略,支持全部升级(All),按集群渐进升级(Progressive Per Cluster)和按集群组渐进升级(Progressive Per Group),并可定义一组 MandatoryDecisionGroups 来优先尝试新配置。
依照 GitOps 的四个原则,我们来看看 OCM 如何支持以 GitOps 的方式应对多集群环境下的升级挑战。
- 声明式
在ClusterManagementAddOn中可以声明 add-on 所使用的配置文件。配置文件可在全局的supportedConfigs中声明,该配置文件会应用到所有的ManagedClusterAddOn实例上。也可在installStrategy下不同的 placements 中声明,每个 Placement 所选择集群的ManagedClusterAddOn将拥有相同的配置文件,placements 中声明的配置会覆盖全局配置。
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
spec:
supportedConfigs:
- defaultConfig:
name: managed-serviceaccount-0.4.0
group: addon.open-cluster-management.io
resource: addontemplates
installStrategy:
placements:
- name: aws-placement
namespace: default
configs:
- group: addon.open-cluster-management.io
resource: addondeploymentconfigs
name: managed-serviceaccount-addon-deploy-config
rolloutStrategy:
type: Progressive
progressive:
mandatoryDecisionGroups:
- groupName: "canary"
maxConcurrency: 1
type: Placements
- 版本控制
add-on 配置文件名称或 spec 内容的变化会被认为是一个配置更改,会触发 add-on 的一次升级。用户可以利用 Kustomize 或 GitOps 来控制配置文件升级。
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: AddOnTemplate
metadata:
name: managed-serviceaccount-0.4.0
spec:
agentSpec: # required
workload:
manifests:
- kind: Deployment
metadata:
name: managed-serviceaccount-addon-agent
namespace: open-cluster-management-agent-addon
...
- kind: ServiceAccount
metadata:
name: managed-serviceaccount
namespace: open-cluster-management-agent-addon
…
registration: # optional
- 自动化
OCM 在 open-cluster-management-hub 命名空间下的组件 addon-manager-controller 是一个更通用的 addon manager,它会 watch 以下两种类型的 add-on 并负责维护此类 add-on 的生命周期,包括安装与升级。当配置文件的名称或者 spec 内容变化时,此组件会按照 rolloutStrategy 所定义的升级策略来升级 add-on。
- Hard 模式:使用最新addon-framework开发的 add-on,需要删除代码中的
WithInstallStrategy()方法并在ClusterManagementAddOn添加 annotationaddon.open-cluster-management.io/lifecycle: "addon-manager"。详细内容参考Add-on 开发指南。 - Easy 模式:使用 AddOnTemplate 模式开发的 add-on。
✗ kubectl get deploy -n open-cluster-management-hub
NAME READY UP-TO-DATE AVAILABLE AGE
cluster-manager-addon-manager-controller 1/1 1 1 10h
cluster-manager-placement-controller 1/1 1 1 10h
cluster-manager-registration-controller 1/1 1 1 10h
cluster-manager-registration-webhook 1/1 1 1 10h
cluster-manager-work-webhook 1/1 1 1 10h
- 持续协调
Add-on 配置文件的 spec hash 会被记录在ClusterManagementAddOn以及ManagedClusterAddOn的 status 中,当 spec hash 变化时,addon-manager-controller 会根据 rolloutStrategy 定义的升级策略持续更新 add-on,直至 lastAppliedConfig,lastKnownGoodConfig 和 desiredConfig 相一致。如下例子中,由于 lastAppliedConfig 与 desiredConfig 不匹配,add-on 状态显示为升级中。
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
…
status:
installProgressions:
- conditions:
- lastTransitionTime: "2023-09-21T06:53:59Z"
message: 1/3 upgrading, 0 timeout.
reason: Upgrading
status: "False"
type: Progressing
configReferences:
- desiredConfig:
name: managed-serviceaccount-0.4.1
specHash: dcf88f5b11bd191ed2f886675f967684da8b5bcbe6902458f672277d469e2044
group: addon.open-cluster-management.io
lastAppliedConfig:
name: managed-serviceaccount-0.4.0
specHash: 1f7874ac272f3e4266f89a250d8a76f0ac1c6a4d63d18e7dcbad9068523cf187
lastKnownGoodConfig:
name: managed-serviceaccount-0.4.0
specHash: 1f7874ac272f3e4266f89a250d8a76f0ac1c6a4d63d18e7dcbad9068523cf187
resource: addontemplates
name: aws-placementl
namespace: default
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ManagedClusterAddOn
metadata:
name: managed-serviceaccount
namespace: cluster1
…
status:
conditions:
- lastTransitionTime: "2023-09-21T06:53:42Z"
message: upgrading.
reason: Upgrading
status: "False"
type: Progressing
configReferences:
- desiredConfig:
name: managed-serviceaccount-0.4.1
specHash: dcf88f5b11bd191ed2f886675f967684da8b5bcbe6902458f672277d469e2044
group: addon.open-cluster-management.io
lastAppliedConfig:
name: managed-serviceaccount-0.4.0
specHash: dcf88f5b11bd191ed2f886675f967684da8b5bcbe6902458f672277d469e2044
lastObservedGeneration: 1
name: managed-serviceaccount-0.4.1
resource: addontemplates
三种升级策略
ClusterManagementAddOn 的rolloutStrategy字段定义了升级的策略,目前 OCM 支持三种类型的升级策略。
- 全部升级(All)
默认的升级类型是 All,意味着新的配置文件会立刻应用于所有的集群。
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
supportedConfigs:
...
installStrategy:
placements:
- name: aws-placement
namespace: default
rolloutStrategy:
type: All
type: Placement
- 按集群渐进升级(Progressive Per Cluster)
Progressive 意味着将新的配置文件依次部署在所选择的每个集群,只有当前集群升级成功后新的配置文件才会应用到下个集群。前面我们介绍了 Placement Decision Group 的概念,MandatoryDecisionGroups 中可以指定一个或多个 Decision Group。如果定义了 MandatoryDecisionGroups,则优先将新的配置文件部署到这些集群组。 MaxConcurrency 定义了同时部署的最大集群数量。
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
supportedConfigs:
...
installStrategy:
placements:
- name: aws-placement
namespace: default
rolloutStrategy:
type: Progressive
progressive:
mandatoryDecisionGroups:
- groupName: "canary"
maxConcurrency: 1
type: Placements
- 按集群组渐进升级(Progressive Per Group)
ProgressivePerGroup 意味着将新的配置文件依次部署在所选择的每个集群组,只有当前集群组升级成功后新的配置文件才会应用到下个集群组。如果定义了 MandatoryDecisionGroups,则优先将新的配置文件部署到这些集群组。如果没有 mandatoryDecisionGroups,则按照集群组的 index 顺序依次升级。
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
supportedConfigs:
...
installStrategy:
placements:
- name: aws-placement
namespace: default
rolloutStrategy:
type: ProgressivePerGroup
progressivePerGroup:
mandatoryDecisionGroups:
- groupName: "canary"
type: Placements
依照 GitOps 的四个原则,和 OCM 的三种升级策略,使用者可以利用 Kustomize 或 GitOps 实现跨集群的无缝滚动/金丝雀升级。值得注意的是,installStrategy 下支持多个 Placement 的定义,使用者可以基于此实现更多高级的升级策略。如下面的例子,可以同时定义两个 Placement 分别选择 aws 与 gcp 上的集群,使得同一个 add-on 在不同的集群中使用不同的配置文件和升级策略。
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
supportedConfigs:
...
installStrategy:
placements:
- name: aws-placement
namespace: default
configs:
- group: addon.open-cluster-management.io
resource: addondeploymentconfigs
name: managed-serviceaccount-addon-deploy-config-aws
rolloutStrategy:
type: ProgressivePerGroup
progressivePerGroup:
mandatoryDecisionGroups:
- groupName: "canary"
type: Placements
- name: gcp-placement
namespace: default
configs:
- group: addon.open-cluster-management.io
resource: addondeploymentconfigs
name: managed-serviceaccount-addon-deploy-config-gcp
rolloutStrategy:
type: ProgressivePerGroup
progressivePerGroup:
mandatoryDecisionGroups:
- groupName: "canary"
type: Placements
三种升级配置
rolloutStrategy升级策略中还可以定义MinSuccessTime, ProgressDeadline和MaxFailures来实现更细粒度的升级配置。
- MinSuccessTime
MinSuccessTime定义了当addon升级成功且未达到MaxFailures时,controller需要等待多长时间才能继续升级下一个集群。默认值是0代码升级成功后立刻升级下一个集群。如下例子中,将按照每5分钟一个集群的速度升级addon。
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
supportedConfigs:
...
installStrategy:
placements:
- name: aws-placement
namespace: default
rolloutStrategy:
type: Progressive
progressive:
mandatoryDecisionGroups:
- groupName: "canary"
maxConcurrency: 1
minSuccessTime: "5m"
type: Placements
- ProgressDeadline
ProgressDeadline定义了controller等待addon升级成功的最大时间,在此时间之后将addon视为超时“timeout”并计入MaxFailures。超过MaxFailures时将停止升级。默认值为“None”代表controller会一直等待addon升级成功。
如下例子中,controller会在每个集群上等待10分钟直到addon升级成功,若超过10分钟未成功,将标记该集群升级状态为timeout。
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
supportedConfigs:
...
installStrategy:
placements:
- name: aws-placement
namespace: default
rolloutStrategy:
type: Progressive
progressive:
mandatoryDecisionGroups:
- groupName: "canary"
maxConcurrency: 1
progressDeadline: "10m"
type: Placements
- MaxFailures
MaxFailures定义了可以容忍的升级失败的集群数量,可以是一个数值或者百分比。集群状态为failed或者timeout均视为升级失败,失败的集群超过MaxFailures后将停止升级。
如下例子中,当有3个addon升级失败或者超过10分钟未升级成功,将停止升级。
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
name: managed-serviceaccount
annotations:
addon.open-cluster-management.io/lifecycle: "addon-manager"
spec:
supportedConfigs:
...
installStrategy:
placements:
- name: aws-placement
namespace: default
rolloutStrategy:
type: Progressive
progressive:
mandatoryDecisionGroups:
- groupName: "canary"
maxConcurrency: 1
maxFailures: 2
progressDeadline: "10m"
type: Placements
小结
本文详细介绍了如何使用 Open Cluster Management 以 GitOps 方式应对多集群环境下工具链的升级挑战。OCM 提供了基于 Kubernetes 的跨多集群和多云的管理平台,通过 Add-on 插件和 Placement API,使得用户能够优雅、平滑地升级整个工具链。同时,OCM 将 add-on 升级视为配置文件的变更,使得用户能够利用 Kustomize 或 GitOps 实现跨集群的无缝滚动/金丝雀升级。此外,OCM 还提供了多种升级策略,包括全部升级(All),按集群渐进升级(Progressive Per Cluster)和按集群组渐进升级(Progressive Per Group),以满足不同的升级需求。
未来计划
在社区中,我们正在计划实现RolloutConfig以提供更细粒度的 rollout 配置,比如 MinSuccessTime, ProgressDeadline, MaxFailures,使得用户可以定义在失败情况下的升级行为,这将为多集群下的升级提供更多的可操作空间。
详解OCM add-on插件
OCM add-on插件概述
OCM (open-cluster-management)是一个专注于Kubernetes应用跨多集群和多云的管理平台, 提供了集群的注册,应用和负载的分发,调度等基础功能。Add-on插件是OCM提供的一种基于基础组建 的扩展机制,可以让Kubernetes生态的应用很容易迁移到OCM平台上,拥有跨多集群多云的编排和调度的能力。
在OCM平台上,add-on插件可以实现不同被管理集群(Spoke)上应用的不同的配置,也可以实现从控制面(Hub) 获取数据到Spoke集群上等功能。比如:你可以使用managed-serviceaccount add-on插件在Spoke集群上将指定的ServiceaCount信息返回给Hub集群,可以使用cluster-proxy add-on插件建立一个从spoke到hub的反向代理通道。
现阶段OCM社区已经有的一些add-on:
- Application lifecycle management add-on插件提供了一套通过Subscriptions订阅channel,将github仓库,Helm release或者对象存储仓库的应用分发到指定Spoke集群上的机制。
- Cluster proxy add-on插件通过反向代理通道提供了Hub和Spoke集群之间L4网络连接。
- Managed service account add-on插件可以让Hub集群管理员很容易管理Spoke集群上serviceaccount。
- Policy framework 和 Policy controllers add-on插件可以让Hub集群管理员很轻松为Spoke集群部署安全相关的policy策略。
- Submarine Addon add-on插件可以让Submarine 和OCM方便集成,为被管理集群提供跨集群的Pod和Service网络互相访问的能力。
- Multicluster Mesh Addon add-on插件为OCM被管理集群提供了跨集群Service Mesh服务。
本文将详细介绍add-on插件的实现机制。
OCM add-on 插件实现机制
通常情况下一个add-on插件包含2部分组成:
Add-on Agent是运行在Spoke集群上的任何Kubernetes资源,比如可以是一个有访问Hub权限的Pod,可以是一个Operator,等等。Add-on Manager是运行中Hub集群上的一个Kubernetes控制器。这个控制器可以通过ManifestWork 来给不同Spoke集群部署分发Add-on Agent所需要的Kubernetes资源, 也可以管理Add-on Agent所需要的权限等。
在OCM Hub集群上,关于add-on插件有2个主要的API:
ClusterManagementAddOn: 这是一个cluster-scoped的API,每个add-on插件必须创建一个同名的实例用来描述add-on插件的名字 和描述信息,以及配置,安装部署策略等。ManagedClusterAddOn: 这是一个namespace-scoped的API,部署到spoke集群的namespace下的和add-on同名的实例用来触发Add-on Agent安装部署到该Spoke集群。我们也可以通过这个API获取这个add-on插件的agent的健康状态信息。
Add-on 插件架构如下:

创建:
Add-on Manager 监控managedClusterAddOn 来创建manifestWork把Add-on Agent部署到Spoke集群上,也可以根据
配置的部署策略只将agent部署到策略选中的集群上。
注册:
如果Add-on Agent 需要访问Hub集群,registration-agent会根据managedClusterAddOn 中的注册信息来向Hub集群
发起CSR请求来申请访问Hub集群的权限,Add-on Manager 根据自定义的approve策略来检查CSR请求,approve后,创建对应的RBAC
权限给agent,registration-agent 会生成一个含有指定权限的kubeconfig secret, agent可以通过这个secret来访问Hub集群。
原生Kubernetes CSR只支持kubernetes.io/kube-apiserver-client,kubernetes.io/kube-apiserver-client-kubelet
和kubernetes.io/kubelet-serving 这几种签名者(signer),我们可以提供让用户自定义证书和签名者来访问非kube-apiserver的服务,
在Add-on Manager上可以自定义验证签名者和证书是否正确来完成add-on的注册。
健康检查:
Add-on Agent可以通过addon-framework提供的lease功能在Spoke集群上维护一个lease,registration-agent 监控这个Lease,
并通过Lease状态判断Agent是否健康,并更新到Hub集群的managedClusterAddOn的Available状态中。用户也可以通过其他自定义方式
来进行agent的健康检查,比如通过Add-on ManifestWork中某个资源的字段来判断agent是否健康。
开发:
OCM 社区提供了一个addon-framework的库, 可以方便开发者快速开发自己的add-on插件Manager,也可以将自己的Kubernetnes 应用通过addon-framework便捷的以add-on插件的 形式迁移到OCM多集群上。
开发者将自己的Agent侧要部署的资源以Helm Chart或者Go Template的形式直接拷贝到工程目录,通过调用addonfactory就可以完成整个add-on注册,配置,健康检查等所有功能。详细请 参考add-on 开发指引.
例子
我们以addon-framework中的helloworldhelm
add-on插件来举例。 这个add-on插件例子是将Hub集群上集群namespace下的configmap同步到Spoke集群上。
首先我们用KinD创建2个集群,一个当Hub集群安装OCM,并将另一个作为Spoke集群,以cluster1的名字注册到Hub集群。 可以参考OCM安装。
$ kubectl get mcl
NAME HUB ACCEPTED MANAGED CLUSTER URLS JOINED AVAILABLE AGE
cluster1 true https://localhost True True 17s
然后在Hub集群上安装helloworldhelm add-on插件的Add-on Manager控制器。 具体步骤参考部署helloworldhelm add-on。
$ kubectl get deployments.apps -n open-cluster-management helloworld-controller
NAME READY UP-TO-DATE AVAILABLE AGE
helloworldhelm-controller 1/1 1 1 50s
在Hub集群上我们可以看到helloworldhelm add-on插件的ClusterManagementAddOn:
$ kubectl get clustermanagementaddons.addon.open-cluster-management.io helloworldhelm -o yaml
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ClusterManagementAddOn
metadata:
creationTimestamp: "2023-05-28T14:12:32Z"
generation: 1
name: helloworldhelm
resourceVersion: "457615"
uid: 29ac6292-7346-4bc9-8013-fd90f40589d6
spec:
addOnMeta:
description: helloworldhelm is an example addon created by helm chart
displayName: helloworldhelm
installStrategy:
type: Manual
supportedConfigs:
- group: addon.open-cluster-management.io
resource: addondeploymentconfigs
- group: ""
resource: configmaps
给cluster1 集群上部署helloworldhelm add-on, agent部署到Spoke集群的open-cluster-management-agent-addon namespace。
$ clusteradm addon enable --names helloworldhelm --namespace open-cluster-management-agent-addon --clusters cluster1
我们看到Hub集群上cluster1的namespace下部署了一个managedClusterAddon:
$ kubectl get managedclusteraddons.addon.open-cluster-management.io -n cluster1 helloworldhelm -o yaml
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ManagedClusterAddOn
metadata:
creationTimestamp: "2023-05-28T14:13:56Z"
finalizers:
- addon.open-cluster-management.io/addon-pre-delete
generation: 1
name: helloworldhelm
namespace: cluster1
ownerReferences:
- apiVersion: addon.open-cluster-management.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: ClusterManagementAddOn
name: helloworldhelm
uid: 29ac6292-7346-4bc9-8013-fd90f40589d6
resourceVersion: "458003"
uid: 84ceac57-3a7d-442f-bc28-d9828023d880
spec:
installNamespace: open-cluster-management-agent-addon
status:
conditions:
- lastTransitionTime: "2023-05-28T14:13:57Z"
message: Registration of the addon agent is configured
reason: SetPermissionApplied
status: "True"
type: RegistrationApplied
- lastTransitionTime: "2023-05-28T14:13:57Z"
message: manifests of addon are applied successfully
reason: AddonManifestApplied
status: "True"
type: ManifestApplied
- lastTransitionTime: "2023-05-28T14:13:57Z"
message: client certificate rotated starting from 2023-05-28 14:08:57 +0000 UTC
to 2024-05-27 14:08:57 +0000 UTC
reason: ClientCertificateUpdated
status: "True"
type: ClusterCertificateRotated
- lastTransitionTime: "2023-05-28T14:15:04Z"
message: helloworldhelm add-on is available.
reason: ManagedClusterAddOnLeaseUpdated
status: "True"
type: Available
namespace: open-cluster-management-agent-addon
registrations:
- signerName: kubernetes.io/kube-apiserver-client
subject:
groups:
- system:open-cluster-management:cluster:cluster1:addon:helloworldhelm
- system:open-cluster-management:addon:helloworldhelm
- system:authenticated
user: system:open-cluster-management:cluster:cluster1:addon:helloworldhelm:agent:8xz2x
supportedConfigs:
- group: ""
resource: configmaps
- group: addon.open-cluster-management.io
resource: addondeploymentconfigs
在Hub集群上的cluster1 namespace下,我们还可以看到部署add-on agent对应的manifestWork。
$ kubectl get manifestwork -n cluster1
NAME AGE
addon-helloworldhelm-deploy-0 7m18s
在Spoke集群cluster1上,我们可以看到agent部署在了open-cluster-management-agent-addon namespace下,
agent通过绑定hub的kubeconfig来访问Hub同步configmap。
$ kubectl get deployments.apps -n open-cluster-management-agent-addon
NAME READY UP-TO-DATE AVAILABLE AGE
helloworldhelm-agent 1/1 1 1 8m17s
$ kubectl get secret -n open-cluster-management-agent-addon
NAME TYPE DATA AGE
helloworldhelm-hub-kubeconfig Opaque 3 8m17s
OCM add-on最新的改进和计划
在最新发布的OCM v0.11.0版本中,我们对add-on进行了很多功能的增强:
- 在Hub集群上有专门的addon-manager 组建来管理add-on插件的配置和生命周期。
- 特别增强了add-on生命周期的管理,升级了
ClusterManagementAddon和ManagedClusterAddOn这两个API, 用户可以通过和Placement结合对指定集群上的add-on进行滚动升级和金丝雀升级。 - 我们还在设计一种新的add-on API AddonTemplate 来让用户不用进行代码开发就可以轻松实现自己的add-on插件的部署安装。
使用OCM让多集群调度更具可扩展性
背景问题
OCM Placement API 可以动态的在多集群环境中选择一组托管集群ManagedCluster,以便将工作负载部署到这些集群上。
在上一篇CNCF 沙箱项目 OCM Placement 多集群调度指南中,我们详细介绍了 Placement 的基本概念,提供的调度功能以及调度流程。同时还通过示例展示了如何在不同的应用场景下使用 Placement API。建议首次接触 Placement 的读者先阅读此文。
Placement 提供了通过标签选择器labelSelector或声明选择器claimSelector过滤集群,同时也提供了一些内置的优选器prioritizer,可对过滤后的集群进行打分排序和优先选择。
内置的prioritizer中包括了最大可分配 CPU 资源(ResourceAllocatableCPU)和最大可分配内存资源(ResourceAllocatableMemory),它们提供了根据集群的可分配 CPU 和内存进行调度的能力。但是,由于集群的"AllocatableCPU"和"AllocatableMemory"是静态值,即使"集群资源不足",它们也不会改变。这导致在实际使用中,这两个prioritizer不能满足基于实时可用 CPU 或内存进行调度的需求。此外,使用者还可能需要根据从集群中获取的资源监控数据进行调度,这些都是内置的prioritizer无法满足的需求。
以上这些需求要求 Placement 能够更灵活的根据第三方数据来进行调度。为此,我们实现了一种更具扩展性的方式来支持基于第三方数据的调度,使用者可以使用自定义的分数来选择集群。
本文将介绍 OCM 是如何让多集群调度更具可扩展性,并通过实例展示如何实现一个第三方数据控制器controller来扩展 OCM 的多集群调度功能。
OCM 如何让调度具有可扩展性
为了实现基于第三方数据的调度,OCM 引入了 API AddOnPlacementScore,它支持存储自定义的集群分数,使用者可以在 Placement 中指定使用此分数选择集群。
如下是一个AddOnPlacementScore的例子,更多关于 API 的细节可访问types_addonplacementscore.go。
apiVersion: cluster.open-cluster-management.io/v1alpha1
kind: AddOnPlacementScore
metadata:
name: default
namespace: cluster1
status:
conditions:
- lastTransitionTime: "2021-10-28T08:31:39Z"
message: AddOnPlacementScore updated successfully
reason: AddOnPlacementScoreUpdated
status: "True"
type: AddOnPlacementScoreUpdated
validUntil: "2021-10-29T18:31:39Z"
scores:
- name: "cpuAvailable"
value: 66
- name: "memAvailable"
value: 55
AddOnPlacementScore的主要内容都在status中,因为我们不希望使用者更新它。AddOnPlacementScore的生命周期维护及scores的更新应该由第三方controller负责。
conditions包括了资源不同的条件状态。scores是一个列表,包含了一组分数的名称和值。在上例中,scores包含了自定义分数 cpuAvailable 和 memAvailable。validUntil定义了scores的有效时间。在此时间之后,分数被 Placement 视为无效,nil 代表永不过期。controller 需要在更新 score 时更新此字段,保证分数是最新状态。
作为使用者,需要知道AddOnPlacementScore的资源名称default和socre名称cpuAvailable memAvailable。之后可在 Placement 中指定用此分数选择集群。
例如,下面的 Placement 想要选择具有最高cpuAvailable分数的前 3 个集群。
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: Placement
metadata:
name: placement
namespace: ns1
spec:
numberOfClusters: 3
prioritizerPolicy:
mode: Exact
configurations:
- scoreCoordinate:
type: AddOn
addOn:
resourceName: default
scoreName: cpuAvailable
weight: 1
32-extensiblescheduling包含了关于此设计的详细内容。
接下来,将用一个示例展示如何实现一个 controller 来更新score,并使用此score选择集群。
示例
示例代码位于 GitHub 仓库resource-usage-collect-addon。它提供的分数可实时反映集群的 CPU 和内存利用率。
示例使用 OCM addon-framework 进行开发,它可以作为一个 addon 插件被安装到每个ManagedCluster上,并将集群的score更新到对应的AddOnPlacementScore中。(本文不涉及 addon 开发细节,详细内容可参考add-on 开发指南。)
resource-usage-collect addon 遵循hub-agent的架构,如下所示。
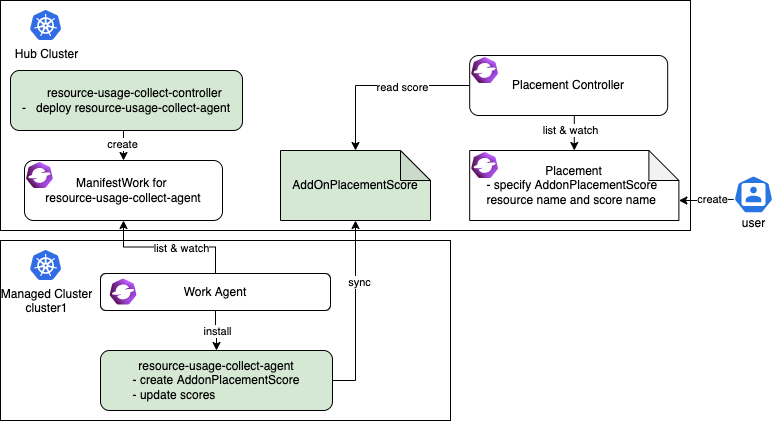
resource-usage-collect addon 包括了一个 hub 上的 manager 和 managed cluster 上的 agent(绿色部分)。
工作流程为:
- hub 上运行 addon 的 manager,它负责在 hub 上为每个 agent 创建部署所需的
ManifestWork。 - 在每个 managed cluster 上,work agent 负责监控 hub 上的
ManifestWork并在 managed cluster 上安装 agent。 - agent 是 addon 的核心部分,它负责为每个 managed cluster 创建
AddonPlacementScore,并每 60 秒刷新一次scores和validUntil。 - 当
AddonPlacementScore创建完成,用户便可以在Placement中指定AddOnPlacementScore的资源名称和score名称,根据分数来选择集群。 - Placement controller 会在每个集群的命名空间中获取
AddOnPlacementScore资源,在scores列表中读取分数,并使用该分数对集群进行打分排序。
上述是AddonPlacementScore和 placement controller 的工作流程,非常容易理解。下面我们来试着运行样例代码。
准备 OCM 环境(包含 2 个ManagedCluster)
curl -sSL https://raw.githubusercontent.com/open-cluster-management-io/OCM/main/solutions/setup-dev-environment/local-up.sh | bash
- 确认两个
ManagedCluster和一个默认的ManagedClusterSet创建完成。
$ clusteradm get clusters
NAME ACCEPTED AVAILABLE CLUSTERSET CPU MEMORY KUBERENETES VERSION
cluster1 true True default 24 49265496Ki v1.23.4
cluster2 true True default 24 49265496Ki v1.23.4
$ clusteradm get clustersets
NAME BOUND NAMESPACES STATUS
default 2 ManagedClusters selected
- 将默认
ManagedClusterSet绑定到 defaultNamespace。
clusteradm clusterset bind default --namespace default
$ clusteradm get clustersets
NAME BOUND NAMESPACES STATUS
default default 2 ManagedClusters selected
安装 resource-usage-collect addon
- 下载源代码。
git clone git@github.com:open-cluster-management-io/addon-contrib.git
cd addon-contrib/resource-usage-collect-addon
- 编译容器镜像。
# Set image name, this is an optional step.
export IMAGE_NAME=quay.io/haoqing/resource-usage-collect-addon:latest
# Build image
make images
如果你使用了 kind,需要手工将镜像加载到 kind 环境中。
kind load docker-image $IMAGE_NAME --name <cluster_name> # kind load docker-image $IMAGE_NAME --name hub
- 部署 resource-usage-collect addon。
make deploy
- 验证安装成功。
在 hub 集群上, 验证 resource-usage-collect-controller pod 运行成功。
$ kubectl get pods -n open-cluster-management | grep resource-usage-collect-controller
resource-usage-collect-controller-55c58bbc5-t45dh 1/1 Running 0 71s
在 hub 集群上, 验证每个 managed cluster 生成了对应的AddonPlacementScore。
$ kubectl get addonplacementscore -A
NAMESPACE NAME AGE
cluster1 resource-usage-score 3m23s
cluster2 resource-usage-score 3m24s
AddonPlacementScore的 status 中应该包含了如下的分数。
$ kubectl get addonplacementscore -n cluster1 resource-usage-score -oyaml
apiVersion: cluster.open-cluster-management.io/v1alpha1
kind: AddOnPlacementScore
metadata:
creationTimestamp: "2022-08-08T06:46:04Z"
generation: 1
name: resource-usage-score
namespace: cluster1
resourceVersion: "3907"
uid: 6c4280e4-38be-4d45-9c73-c18c84799781
status:
scores:
- name: cpuAvailable
value: 12
- name: memAvailable
value: 4
如果AddonPlacementScore没有生成或者 status 中没有分数,可以登陆到 managed cluster 上,检查 resource-usage-collect-agent pod 是否正常运行。
$ kubectl get pods -n default | grep resource-usage-collect-agent
resource-usage-collect-agent-5b85cbf848-g5kqm 1/1 Running 0 2m
通过自定义分数选择集群
如果上述步骤运行正常,接下来我们可以试着创建一个Placement并通过自定义分数选择集群。
- 创建一个
Placement选择具有最高 cpuAvailable 分数的集群。
当scoreCoordinate的类型type定义为AddOn时,placement controller 会在每个集群的命名空间中获取名称为resource-usage-score的AddOnPlacementScore资源,在scores列表中读取分数cpuAvailable,并使用该分数对集群进行打分排序。
cat << EOF | kubectl apply -f -
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: Placement
metadata:
name: placement1
namespace: default
spec:
numberOfClusters: 1
clusterSets:
- default
prioritizerPolicy:
mode: Exact
configurations:
- scoreCoordinate:
type: AddOn
addOn:
resourceName: resource-usage-score
scoreName: cpuAvailable
weight: 1
EOF
- 验证
PlacementDecision。
$ kubectl describe placementdecision -n default | grep Status -A 3
Status:
Decisions:
Cluster Name: cluster1
Reason:
可以看到 Cluster1 被选中,出现在PlacementDecision的结果中。
运行如下命令获取AddonPlacementScore的自定义分数。可以看到"cpuAvailable"的分数是 12。
$ kubectl get addonplacementscore -A -o=jsonpath='{range .items[*]}{.metadata.namespace}{"\t"}{.status.scores}{"\n"}{end}'
cluster1 [{"name":"cpuAvailable","value":12},{"name":"memAvailable","value":4}]
cluster2 [{"name":"cpuAvailable","value":12},{"name":"memAvailable","value":4}]
在Placement的 events 也可以看到集群的分数是 12 分。这表明自定义分数被直接用于对集群进行打分和排序。由于上述 placement 中 numberOfClusters 定义为 1,最终只有 cluster1 被选中。
$ kubectl describe placement -n default placement1 | grep Events -A 10
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal DecisionCreate 50s placementController Decision placement1-decision-1 is created with placement placement1 in namespace default
Normal DecisionUpdate 50s placementController Decision placement1-decision-1 is updated with placement placement1 in namespace default
Normal ScoreUpdate 50s placementController cluster1:12 cluster2:12
如何实现自定义分数控制器
现在你已经知道了如何安装 resource-usage-collect addon 并使用自定义分数来选择群集。接下来,让我们深入了解在实现自定义分数控制器controller时需要考虑的一些关键点。
1. 在哪里运行自定义分数控制器 (controller)
Controller 可以在 hub 集群或 managed cluster 上运行。可以结合具体的使用场景,选择将 controller 运行在何处。
比如,在我们的示例中,自定义分数控制器controller是使用 addon-famework 开发的,它遵循 hub-agent 架构。resource-usage-collect-agent 真正运行自定义分数程序,它安装在每个 managed cluster 上,获取 managed cluster 的可用 CPU 和内存,计算分数,并将其更新到AddonPlacementScore中。resource-usage-collect-controller 只负责安装代理 agent。
在其他情况下,例如,如果想使用 Thanos 中的指标为每个 managed cluster 计算得分,则自定义分数控制器controller需要放置在 hub 上,因为 Thanos 有从每个 managed cluster 收集的所有指标。
2. 如何维护AddOnPlacementScore的生命周期
在我们的示例中,维护AddonPlacementScore的代码位于pkg/addon/agent/agent.go中。
-
何时创建
AddonPlacementScore?AddonPlacementScore可以在 managed cluster 创建完成后创建,或者按需创建以减少 hub 上的 resource。在上述示例中,addon 在 managed cluster 创建完成后,为每个 managed cluster 创建对应的
AddonPlacementScore,并且生成初始分数。 -
何时更新
AddonPlacementScore?可以在监视数据发生变化时更新分数,或者至少在
ValidUntil到期之前更新分数。 我们建议在更新分数时设置ValidUntil,以便 placement controller 可以知道分数是否仍然有效,防止分数长时间未能更新的情况。在上述示例中,除了每 60 秒重新计算和更新分数外,当 managed cluster 中的节点或 Pod 资源发生更改时,也将触发更新。
3. 如何计算分数
计算分数的代码位于pkg/addon/agent/calculate.go。有效的得分必须在-100 至 100 的范围内,你需要在将分数更新到AddOnPlacementScore之前将其归一化。在归一化分数时,可能会遇到以下情况。
-
分数提供程序知道自定义分数的最大值和最小值。
在这种情况下,可以通过公式轻松实现平滑映射。假设实际值为 X,并且 X 在间隔[min,max]中,则得分=200 *(x-min)/(max-min)-100
-
分数提供程序不知道自定义分数的最大值和最小值。
在这种情况下,需要自己设置最大值和最小值,因为如果没有最大值和最小值,则无法将单个值 X 映射到范围[-100,100]。 然后,当 X 大于此最大值时,可以认为群集足够健康可以部署应用程序,可以将分数设置为 100。如果 X 小于最小值,则可以将分数设置为-100。
if X >= max score = 100 if X <= min score = -100
在我们的示例中,运行在每个托管群集上的 resource-usage-collect-agent 没有全局视角,无法知道所有群集的 CPU/内存使用率的最大值/最小值,因此我们在代码中手动将最大值设置为MAXCPUCOUNT和MAXMEMCOUNT,最小值设置为 0。分数计算公式可以简化为:score = x / max * 100。
总结
在本文中,我们介绍了什么是OCM的可扩展调度,并使用示例展示了如何实现自定义分数控制器。此外,本文列出了开发者在实现第三方分数控制器时需要考虑的3个关键点。希望阅读本文后,您可以清楚地了解到如何使用OCM 来扩展多集群调度能力。
How to distribute workloads using Open Cluster Management
Read more at Red Hat Developers.
KubeCon NA 2022 - OCM Multicluster App & Config Management
Read more at KubeCon NA 2022 - OCM Multicluster App & Config Management.
KubeCon NA 2022 - OCM Workload distribution with Placement API
Read more at KubeCon NA 2022 - OCM Workload distribution with Placement API.
Karmada and Open Cluster Management: two new approaches to the multicluster fleet management challenge
Read more at CNCF Blog.
Extending the Multicluster Scheduling Capabilities with Open Cluster Management Placement
Read more at Red Hat Cloud Blog.
详解ocm klusterlet秘钥管理机制
概述
在open-cluster-management中,为了使控制面有更好的可扩展性,我们使用了hub-spoke的架构:即集中的控制面(hub只
负责处理控制面的资源和数据而无需访问被管理的集群;每个被管理集群(spoke)运行一个称为klusterlet的agent访问控制面获取
需要执行的任务。在这个过程中,klusterlet需要拥有访问hub集群的秘钥才能和hub安全通信。确保秘钥的安全性是非常重要的,
因为如果这个秘钥被泄露的话有可能导致对hub集群的恶意访问或者窃取敏感信息,特别是当ocm的被管理集群分布在不同的公有云中的时候。
为了保证秘钥的安全性,我们需要满足一些特定的需求:
- 尽量避免秘钥在公有网络中的传输
- 秘钥的刷新和废除
- 细粒度的权限控制
本文将详细介绍ocm是如何实现秘钥的管理来保证控制面板和被管理集群之间的安全访问的。
架构和机制
在ocm中我们采用了以下几个机制来确保控制面和被管理集群之间访问的安全性:
- 基于
CertificateSigniningRequest的mutual tls - 双向握手协议和动态
klusterletID - 认证和授权的分离
基于CertificateSigniningRequest的mutual tls
使用kubernetes的CertificateSigniningRequest(CSR)API可以方便的生成客户认证证书。这个机制可以让klusterlet在第一次
启动访问hub集群时使用一个权限很小的秘钥来创建CSR。当CSR返回了生成的证书后,klusterlet就可以用后续生成的带有更大访问权限的
证书来访问hub集群。在使用csr的过程中,klusterlet的私钥不会在网络中传输而是一直保存在被管理集群中;只有CSR的公钥和初始阶段需要的
小权限秘钥(bootstrap secret)会在不同集群间传输。这就最大程度的保证秘钥不会在传输过程中被泄露出去。
双向握手协议和动态klusterletID
那么如果初始阶段的bootstrap secret被泄露了会怎么样呢?这就牵涉到OCM中的双向握手协议。当被管理集群中的klusterlet使用bootstrap secret
发起了第一次请求的时候, hub集群不会立刻为这个请求创建客户证书和对应的访问权限。这个请求将处在Pending状态,直到hub集群拥有特定管理权限的管理员
同意了klusterlet的接入请求后,客户证书和特定权限才会被创建出来。这个请求中包含了klusterlet启动阶段生成的动态ID,管理员需要确保这个ID和被
管理集群上klusterlet的ID一致才能同意klusterlet的接入。这也就确保了如果bootstrap secret被不慎泄露后,CSR也不会被管理员轻易的接受。
klusterlet使用的客户证书是有过期时间的,klusterlet需要在证书过期之前使用现有的客户证书发起新的CSR请求来获取新的客户证书。hub集群会检验
更新证书的CSR请求是否合法并自动签署新的客户证书。需要注意的是由于klusterlet使用了动态ID的机制,只有klusterlet本身发起的CSR请求才会
被自动签署。如果klusterlet在集群中被卸载然后重新部署后,它必须重新使用bootstrap secret流程来获取客户证书。
认证和授权的分离
在klusterlet的CSR请求被接受后,它获得了被hub集群认证通过的客户证书,但是它在这个时候还没有对hub集群上特定资源访问的权限。
ocm中还有一个单独的授权流程。每个被管理集群的klusterlet时候有权限访问hub集群的特定资源是被对应ManagedClusterAPI上的
hubAcceptsClient域来控制的。只有当这个域被置位true时,hub集群的控制器才会为对应klusterlet赋予权限。而设置这个域需要用户
在hub集群中对managedcluster/accept具有update权限才可以。如下面的clusterrole的例子表示用户只能对cluster1这个
ManagedCluster上的klusterlet赋予权限。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: open-cluster-management:hub
rules:
- apiGroups: ["register.open-cluster-management.io"]
resources: ["managedclusters/accept"]
verbs: ["update"]
resourceNames: ["cluster1"]
将认证和授权的流程分开的原因是通常情况下hub集群具有approve CSR权限的用户和"允许klusterlet接入hub"集群的用户并不完全一致。以上
机制就可以保证即使用户拥有approve CSR的权限也不能给任意的klusterlet赋予接入hub集群的权限。
实现细节
所有认证授权和秘钥管理的代码实现都在registration组件中。大概的流程 如下图所示
当registration-agent在被管理集群中启动后,会首先在自己的namespace里查找是否有hub-kubeconfig的秘钥并验证这个秘钥是否合法。
如果不存在或者不合法,registration-agent就进入了bootstrap流程,它会首先产生一个动态的agent ID, 然后使用一个更小权限的
bootstrap-kubeconfig来创建client和informer,接下来启动一个ClientCertForHubController的goroutine。这个controller会在hub集群
创建CSR,等待CSR中签署的证书并最终把证书和私钥做为名为hub-kubeconfig的秘钥持久化在被管理集群中。agent接着持续监控hub-kubeconfig
这个秘钥是否已经被持久化。当agent发现hub-kubeconfig则意味着agent已经获取到了可以访问hub集群的客户证书,agent就会停掉之前的controller并
退出bootstrap流程。接下来agent会重新用hub-kubeconfig创建client和informer,并启动一个新的ClientCertForHubController的goroutine
来定期刷新客户证书。
在hub集群中的registration-controller会启动CSRApprovingController用来负责检查klusterlet发起的CSR请求是否可以自动签发;以及
managedClusterController用来检查对应ManagedCluster上的hubAccepctsClient域是否被设置并在hub集群中创建相应的权限。
通过OCM访问不同VPC下的集群
问题背景
当我们拥有多个集群时,一个很常见的需求是:不同的用户希望能访问位于不同VPC下的集群。比如,开发人员希望能够在测试集群部署应用,或者运维人员希望能够在生产集群上进行故障排查。
作为多个集群的管理员,为了实现该需求,需要在各个集群为用户:
- 绑定Role。
- 提供访问配置(证书或Token)。
- 提供访问入口。
但是,这种方式有以下几个问题:
- 网络隔离:集群位于私有数据中心,那么管理员就需要为集群用户进行特殊的网络配置,比如建立VPN或者跳板机。
- 网络安全:为用户暴露的集群端口,会增加集群的安全风险。
- 配置过期:证书中的秘钥和Token都有过期时间,管理员需要定期为用户做配置更新。
而通过安装OCM以及cluster-proxy,managed-serviceaccount两个插件,管理员则可以在不暴露集群端口的情况下,为不同用户提供统一访问入口,并方便地管理不同用户的访问权限。
基本概念
以下,我们通过一个简单的例子来解释OCM以及cluster-proxy,managed-serviceaccount的基本概念。
假设我们有3个集群,分别位于两个不同的VPC中,其中VPC-1中的集群可以被所有用户访问,而VPC-2中的2个集群只能被管理员访问。
管理员希望通过VPC-1中的集群(后文称“管理集群”)为用户提供统一的访问入口,使用户可以访问VPC-2中的集群(后文称“受管集群”)。
OCM是什么?
OCM 全称为 Open Cluster Management,旨在解决多集群场景下的集群注册管理,工作负载分发,以及动态的资源配置等功能。
安装OCM之后,我们可以将受管集群注册加入管理集群,完成注册后,在管理集群中会创建一个与受管集群注册名相同的命名空间。比如,受管集群以cluster1注册到管理集群,那么就会对应创建一个名为cluster1的命名空间。在管理集群上,我们可以通过这些不同的命令空间来区分多个受管集群的资源。
注册过程不要求受管集群向管理集群暴露访问接口。
更多有关于OCM的架构细节,请参考官方文档。
cluster-proxy是什么?
cluster-proxy是使用OCM的addon-framework实现的一个基于 apiserver-network-proxy(后文简写为:ANP)的插件。插件安装后,会在管理集群上安装ANP的组件proxy-server,在受管集群上安装ANP的组件proxy-agent。
接着proxy-agent通过管理集群上暴露的端口,向proxy-server发送注册请求,并建立一条全双工通信的GRPC管道。
需要注意的是,cluster-proxy建立的GRPC通道只是保证了管理集群到被管理集群的网络连通性,如果用户想访问被管理集群的APIServer或者其他服务,仍需要从被管理集群获得相应的认证秘钥和权限。
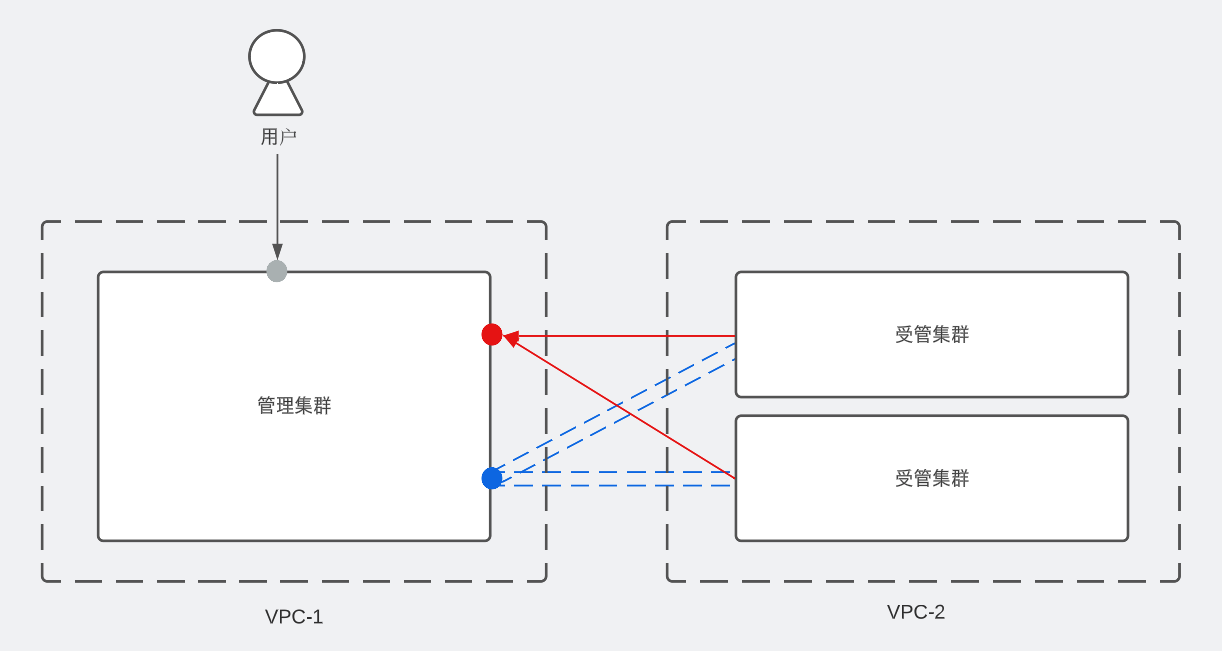
更多有关cluster-proxy的信息,请参考官方文档。
managed-serviceaccount是什么?
Managed-serviceaccount(后文简写为:MSA)也是利用OCM的addon-framework实现的插件。
安装该插件后,可以在管理集群上配置ManagedServiceAcccount的CR,插件会根据此CR的spec配置,在目标受管集群的open-cluster-management-managed-serviceaccount命名空间内,创建一个与CR同名的ServiceAccount。
接着插件会将此ServiceAccount生成的对应token数据同步回管理集群,并在受管集群的命令空间中创建一个同名的Secret,用于保存该token。整个token的数据同步都是在OCM提供的MTLS连接中进行,从而确保token不会被第三方探查到。
由此集群管理员可以在hub上通过MSA来获得访问被管理集群APIServer的token。当然这个token现在还没有被赋予权限,只要管理员为该token绑定相应的Role,就可以实现访问被管理集群的权限控制。
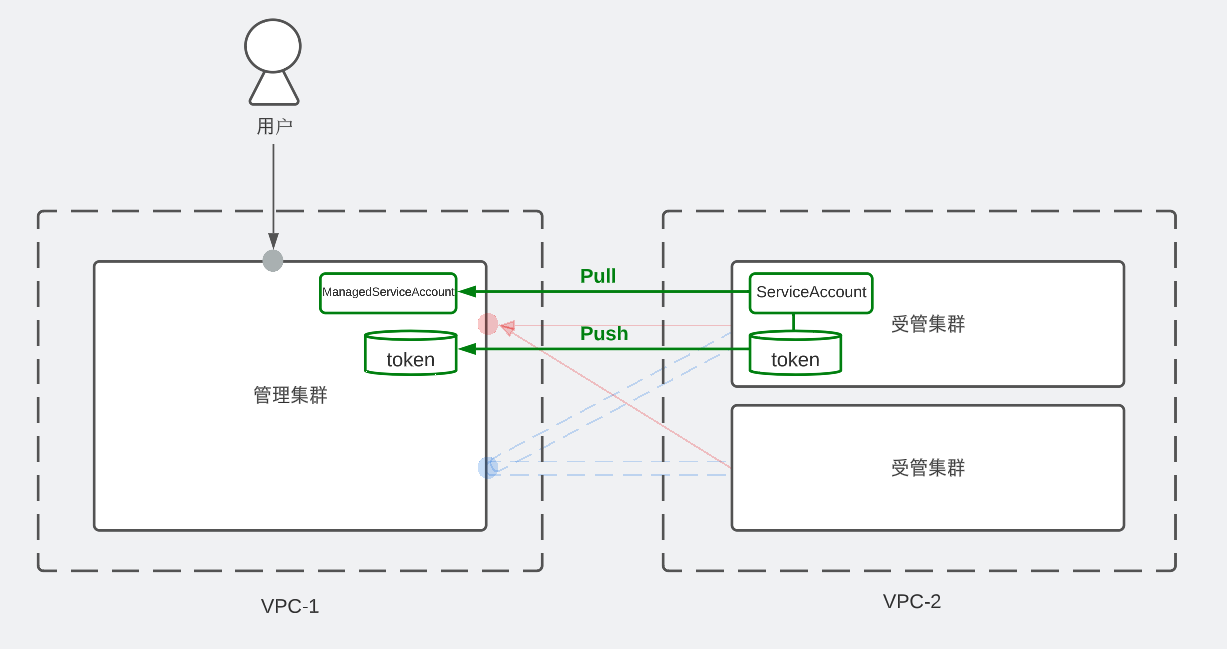
更多有关managed-serviceaccount的信息,请参考官方文档。
样例
接下来通过一个简单的例子来演示如何使用OCM,cluster-proxy,managed-serviceaccount来实现跨VPC访问集群。
首先从管理员视角,我们通过脚本快速创建一个基于kind的多集群环境,其中具有一个管理集群(hub),以及两个受管集群(cluster1, cluster2)。并且 cluster1, cluster2 会通过 OCM 注册到了 hub。
该脚本还会为我们安装OCM的CLI工具clusteradm。
curl -L <https://raw.githubusercontent.com/open-cluster-management-io/OCM/main/solutions/setup-dev-environment/local-up.sh> | bash
然后,管理员还需要安装两个插件:
# 安装 cluster-proxy
helm install \\
-n open-cluster-management-addon --create-namespace \\
cluster-proxy ocm/cluster-proxy
# 安装 managed-service
helm install \\
-n open-cluster-management-addon --create-namespace \\
managed-serviceaccount ocm/managed-serviceaccount
# 验证 cluster-proxy 已安装
clusteradm get addon cluster-proxy
# 验证 managed-serviceaccount 已安装
clusteradm get addon managed-serviceaccount
完成安装后,管理员希望给用户能够访问cluster1,他需要通过以下命令创建一个在hub的命令空间cluster1中,创建一个MSA的CR:
kubectl apply -f - <<EOF
apiVersion: authentication.open-cluster-management.io/v1alpha1
kind: ManagedServiceAccount
metadata:
name: dep
namespace: cluster1
spec:
rotation: {}
EOF
# 检查Token是否已同步回管理集群hub,并保存为名为dep的Secret
kubectl get secret -n cluster1
NAME TYPE DATA AGE
default-token-r89gs kubernetes.io/service-account-token 3 6d22h
dep Opaque 2 6d21h
接着,管理员需要通过OCM的Manifestwork, 即工作负载分发功能,在cluster1上创建一个ClusterRole,给dep绑定了cluster1上的对应权限:
# 创建ClusterRole, 仅具有操作Deployment的权限
clusteradm create work dep-role --cluster cluster1 -f - <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: dep-role
rules:
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["get", "watch", "list", "create", "update", "patch", "delete"]
EOF
# 绑定ClusterRole
clusteradm create work dep-rolebinding --cluster cluster1 -f - <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: dep-rolebinding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: dep-role
subjects:
- kind: ServiceAccount
name: dep
namespace: open-cluster-management-managed-serviceaccount
EOF
完成之后,用户便可以通过cluteradm,来操作cluster1上Deployments了:
clusteradm proxy kubectl --cluster=cluster1 --sa=dep -i
Please enter the kubectl command and use "exit" to quit the interactive mode
kubectl> get deployments -A
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
kube-system coredns 2/2 2 2 20d
local-path-storage local-path-provisioner 1/1 1 1 20d
open-cluster-management-agent klusterlet-registration-agent 1/1 1 1 20d
open-cluster-management-agent klusterlet-work-agent 1/1 1 1 20d
open-cluster-management-cluster-proxy cluster-proxy-proxy-agent 3/3 3 3 20d
open-cluster-management-managed-serviceaccount managed-serviceaccount-addon-agent 1/1 1 1 20d
open-cluster-management klusterlet 3/3 3 3 20d
# 用户没有权限访问cluster1上的pods,请求被拒绝
kubectl> get pods -A
Error from server (Forbidden): pods is forbidden: User "system:serviceaccount:open-cluster-management-managed-serviceaccount:dep" cannot list resource "pods" in API group "" at the cluster scope
值得注意的是,为使用clusteradm访问cluster1, 还需要为用户配置了以下权限:
# 获取MSA的token
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: user
namespace: cluster1
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
- apiGroups: ["authentication.open-cluster-management.io"]
resources: ["managedserviceaccounts"]
verbs: ["get"]
---
# 通过portforward的在本地映射cluster-proxy的Service
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: user-cluster-proxy
namespace: open-cluster-management-cluster-proxy
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list"]
- apiGroups: [""]
resources: ["pods/portforward"]
verbs: ["create"]
---
# 运行命令前对相关Resource进行检查
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: user
rules:
- apiGroups: ["cluster.open-cluster-management.io"]
resources: ["managedclusters"]
verbs: ["get, "list"]
- apiGroups: ["addon.open-cluster-management.io"]
resources: ["clustermanagementaddons"]
verbs: ["get"]
- apiGroups: ["proxy.open-cluster-management.io"]
resources: ["managedproxyconfigurations"]
verbs: ["get"]
总结
本文介绍了如何使用OCM来为用户提供访问不同VPC下集群的功能,通过这种方式,管理员不再需要对集群网络进行特殊配置,也不再需要为用户提供和维护多个集群的访问凭证,所有用户都通过统一的访问接口访问各个集群,增加了系统的安全性和易用性。
目前,OCM的cluster-proxy和managed-serviceaccount功能还处于初期阶段,未来我们还不断的完善其功能,欢迎大家试用并提出宝贵的意见和建议。
Using the Open Cluster Management Placement for Multicluster Scheduling
Read more at Red Hat Cloud Blog.
Using the Open Cluster Management Add-on Framework to Develop a Managed Cluster Add-on
Read more at Red Hat Cloud Blog.
The Next Kubernetes Frontier: Multicluster Management
Read more at Container Journal.
Put together a user walk through for the basic Open Cluster Management API using `kind`, `olm`, and other open source technologies
Read more at GitHub.
Setting up Open Cluster Management the hard way
Read more at Setting up Open Cluster Management the hard way.