Extend the multicluster scheduling capabilities with placement
The Placement API is used to dynamically select a set of ManagedCluster in one or multiple ManagedClusterSets so that the workloads can be deployed to these clusters. You can use placement to filter clusters by label or claim selector, also placement provides some default prioritizers which can be used to sort and select the most suitable clusters.
One of the default prioritizers are ResourceAllocatableCPU and ResourceAllocatableMemory. They provide the capability to sort clusters based on the allocatable CPU and memory. However, when considering the resource based scheduling, there’s a gap that the cluster’s “AllocatableCPU” and “AllocatableMemory” are static values that won’t change even if “the cluster is running out of resources”. And in some cases, the prioritizer needs more extra data to calculate the score of the managed cluster. For example, there is a requirement to schedule based on resource monitoring data from the cluster. For this reason, we need a more extensible way to support scheduling based on customized scores.
What is Placement extensible scheduling?
OCM placement introduces an API AddOnPlacementScore to support scheduling based on customized scores. This API supports storing the customized scores and being used by placement. Details of the API’s definition refer to types_addonplacementscore.go. An example of AddOnPlacementScore is as below.
apiVersion: cluster.open-cluster-management.io/v1alpha1
kind: AddOnPlacementScore
metadata:
name: default
namespace: cluster1
status:
conditions:
- lastTransitionTime: "2021-10-28T08:31:39Z"
message: AddOnPlacementScore updated successfully
reason: AddOnPlacementScoreUpdated
status: "True"
type: AddOnPlacementScoreUpdated
validUntil: "2021-10-29T18:31:39Z"
scores:
- name: "cpuAvailable"
value: 66
- name: "memAvailable"
value: 55
conditions. Conditions contain the different condition statuses for thisAddOnPlacementScore.validUntil. ValidUntil defines the valid time of the scores. After this time, the scores are considered to be invalid by placement. nil means never expire. The controller owning this resource should keep the scores up-to-date.scores. Scores contain a list of score names and values of this managed cluster. In the above example, the API contains a list of customized scores: cpuAvailable and memAvailable.
All the customized scores information is stored in status, as we don’t expect end users to update it.
- As a score provider, a 3rd party controller could run on either hub or managed cluster, to maintain the lifecycle of
AddOnPlacementScoreand update the score into thestatus. - As an end user, you need to know the resource name “default” and customized score name “cpuAvailable"and “memAvailable” , so you can specify the name in placement yaml to select clusters. For example, the below placement wants to select the top 3 clusters with the highest cpuAvailable score.
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: numberOfClusters: 3 prioritizerPolicy: mode: Exact configurations: - scoreCoordinate: type: AddOn addOn: resourceName: default scoreName: cpuAvailable weight: 1 - In placement, if the end-user defines the scoreCoordinate type as AddOn, the placement controller will get the
AddOnPlacementScoreresource with the name “default” in each cluster’s namespace, read score “cpuAvailable” in the score list, and use that score to sort clusters.
You can refer to the enhancements to learn more details about the design. In the design, how to maintain the lifecycle (create/update/delete) of the AddOnPlacementScore CRs is not covered, as we expect the customized score provider itself to manage it. In this article, we will use an example to show you how to implement a 3rd part controller to update your own scores and extend the multiple clusters scheduling capability with your own scores.
How to implement a customized score provider
The example code is in GitHub repo resource-usage-collect-addon. It provides the score of the cluster’s available CPU and available memory, which can reflect the cluster’s real-time resource utilization. It is developed with OCM addon-framework and can be installed as an addon plugin to update customized scores into AddOnPlacementScore. (This article won’t talk many details about addon-framework, referring to Add-on Developer Guide to learn how to develop an addon.)
The resource-usage-collect addon follows the hub-agent architecture as below.
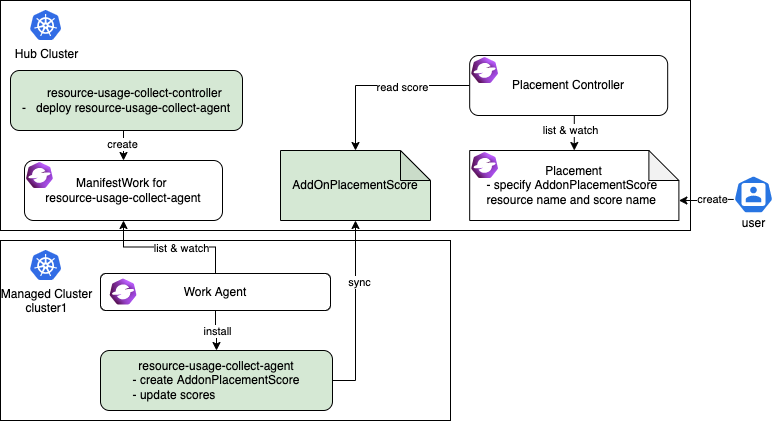
The resource-usage-collect addon contains a controller and an agent.
- On the hub cluster, the resource-usage-collect-controller is running. It is responsible for creating the
ManifestWorkfor resource-usage-collect-agent in each cluster namespace. - On each managed cluster, the work agent watches the
ManifestWorkand installs the resource-usage-collect-agent on each cluster. The resource-usage-collect-agent is the core part of this addon, it creates theAddonPlacementScorefor each cluster on the Hub cluster, and refreshes thescoresandvalidUntilevery 60 seconds.
When the AddonPlacementScore is ready, the end user can specify the customized core in a placement to select clusters.
The working flow and logic of resource-usage-collect addon are quite easy to understand. Now let’s follow the below steps to get started!
Prepare an OCM environment with 2 ManagedClusters.
- Following setup dev environment by kind to prepare an environment.
curl -sSL https://raw.githubusercontent.com/open-cluster-management-io/OCM/main/solutions/setup-dev-environment/local-up.sh | bash
- Confirm there are 2
ManagedClusterand a defaultManagedClusterSetcreated.
$ clusteradm get clusters
NAME ACCEPTED AVAILABLE CLUSTERSET CPU MEMORY KUBERNETES VERSION
cluster1 true True default 24 49265496Ki v1.23.4
cluster2 true True default 24 49265496Ki v1.23.4
$ clusteradm get clustersets
NAME BOUND NAMESPACES STATUS
default 2 ManagedClusters selected
- Bind the default
ManagedClusterSetto defaultNamespace.
clusteradm clusterset bind default --namespace default
$ clusteradm get clustersets
NAME BOUND NAMESPACES STATUS
default default 2 ManagedClusters selected
Install the resource-usage-collect addon.
- Git clone the source code.
git clone git@github.com:open-cluster-management-io/addon-contrib.git
cd addon-contrib/resource-usage-collect-addon
- Prepare the image.
# Set image name, this is an optional step.
export IMAGE_NAME=quay.io/haoqing/resource-usage-collect-addon:latest
# Build image
make images
If your are using kind, load image into kind cluster.
kind load docker-image $IMAGE_NAME --name <cluster_name> # kind load docker-image $IMAGE_NAME --name hub
- Deploy the resource-usage-collect addon.
make deploy
- Verify the installation.
On the hub cluster, verify the resource-usage-collect-controller pod is running.
$ kubectl get pods -n open-cluster-management | grep resource-usage-collect-controller
resource-usage-collect-controller-55c58bbc5-t45dh 1/1 Running 0 71s
On the hub cluster, verify the AddonPlacementScore is generated for each managed cluster.
$ kubectl get addonplacementscore -A
NAMESPACE NAME AGE
cluster1 resource-usage-score 3m23s
cluster2 resource-usage-score 3m24s
The AddonPlacementScore status should contain a list of scores as below.
$ kubectl get addonplacementscore -n cluster1 resource-usage-score -oyaml
apiVersion: cluster.open-cluster-management.io/v1alpha1
kind: AddOnPlacementScore
metadata:
creationTimestamp: "2022-08-08T06:46:04Z"
generation: 1
name: resource-usage-score
namespace: cluster1
resourceVersion: "3907"
uid: 6c4280e4-38be-4d45-9c73-c18c84799781
status:
scores:
- name: cpuAvailable
value: 12
- name: memAvailable
value: 4
If AddonPlacementScore is not created or there are no scores in the status, go into the managed cluster, and check if the resource-usage-collect-agent pod is running well.
$ kubectl get pods -n default | grep resource-usage-collect-agent
resource-usage-collect-agent-5b85cbf848-g5kqm 1/1 Running 0 2m
Select clusters with the customized scores.
If everything is running well, now you can try to create placement and select clusters with the customized scores.
- Create a placement to select 1 cluster with the highest cpuAvailable score.
cat << EOF | kubectl apply -f -
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: Placement
metadata:
name: placement1
namespace: default
spec:
numberOfClusters: 1
clusterSets:
- default
prioritizerPolicy:
mode: Exact
configurations:
- scoreCoordinate:
type: AddOn
addOn:
resourceName: resource-usage-score
scoreName: cpuAvailable
weight: 1
EOF
- Verify the placement decision.
$ kubectl describe placementdecision -n default | grep Status -A 3
Status:
Decisions:
Cluster Name: cluster1
Reason:
Cluster1 is selected by PlacementDecision.
Running below command to get the customized score in AddonPlacementScore and the cluster score set by Placement.
You can see that the “cpuAvailable” score is 12 in AddonPlacementScore, and this value is also the cluster score in Placement events, this indicates that placement is using the customized score to select clusters.
$ kubectl get addonplacementscore -A -o=jsonpath='{range .items[*]}{.metadata.namespace}{"\t"}{.status.scores}{"\n"}{end}'
cluster1 [{"name":"cpuAvailable","value":12},{"name":"memAvailable","value":4}]
cluster2 [{"name":"cpuAvailable","value":12},{"name":"memAvailable","value":4}]
$ kubectl describe placement -n default placement1 | grep Events -A 10
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal DecisionCreate 50s placementController Decision placement1-decision-1 is created with placement placement1 in namespace default
Normal DecisionUpdate 50s placementController Decision placement1-decision-1 is updated with placement placement1 in namespace default
Normal ScoreUpdate 50s placementController cluster1:12 cluster2:12
Now you know how to install the resource-usage-collect addon and consume the customized score to select clusters. Next, let’s take a deeper look into some key points when you consider implementing a customized score provider.
1. Where to run the customized score provider
The customized score provider could run on either hub or managed cluster. Combined with user stories, you should be able to distinguish whether the controller should be placed in a hub or a managed cluster.
In our example, the customized score provider is developed with addon-famework, it follows the hub-agent architecture. The resource-usage-collect-agent is the real score provider, it is installed on each managed cluster, it gets the available CPU and memory of the managed cluster, calculates a score, and updates it into AddonPlacementScore. The resource-usage-collect-controller just takes care of installing the agent.
In other cases, for example, if you want to use the metrics from Thanos to calculate a score for each cluster, then the customized score provider only needs to be placed on the hub, as Thanos has all the metrics collected from each managed cluster.
2. How to maintain the AddOnPlacementScore CR lifecycle
In our example, the code to maintain the AddOnPlacementScore CR is in pkg/addon/agent/agent.go.
-
When should the score be created?
The
AddOnPlacementScoreCR can be created with the existence of a ManagedCluster, or on demand for the purpose of reducing objects on the hub.In our example, the addon creates an
AddOnPlacementScorefor each Managed Cluster if it does not exist, and a score will be calculated when creating the CR for the first time. -
When should the score be updated?
We recommend that you set
ValidUntilwhen updating the score so that the placement controller can know if the score is still valid in case it failed to update for a long time.The score could be updated when your monitoring data changes, or at least you need to update it before it expires.
In our example, in addition to recalculate and update the score every 60 seconds, the update will also be triggered when the node or pod resource in the managed cluster changes.
3. How to calculate the score
The code to calculate the score is in pkg/addon/agent/calculate.go. A valid score must be in the range -100 to 100, you need to normalize the scores before updating it into AddOnPlacementScore.
When normalizing the score, you might meet the below cases.
-
The score provider knows the max and min value of the customized scores.
In this case, it is easy to achieve smooth mapping by formula. Suppose the actual value is X, and X is in the interval [min, max], then
score = 200 * (x - min) / (max - min) - 100. -
The score provider doesn’t know the max and min value of the customized scores.
In this case, you need to set a maximum and minimum value by yourself, as without a max and min value, is unachievable to map a single value X to the range [-100, 100].
Then when the X is greater than this maximum value, the cluster can be considered healthy enough to deploy applications, and the score can be set as 100. And if X is less than the minimum value, the score can be set as -100.
if X >= max score = 100 if X <= min score = -100
In our example, the resource-usage-collect-agent running on each managed cluster doesn’t have a whole picture view to know the max/min value of CPU/memory usage of all the clusters, so we manually set the max value as MAXCPUCOUNT and MAXMEMCOUNT in code, min value is set as 0. The score calculation formula can be simplified: score = x / max * 100.
Summary
In this article, we introduced what is the placement extensible scheduling and used an example to show how to implement a customized score provider. Also, this article list 3 key points the developer needs to consider when implementing a 3rd party score provider. Hope after reading this article, you can have a clear view of how placement extensible scheduling can help you extend the multicluster scheduling capabilities.
Feel free to raise your question in the Open-cluster-management-io GitHub community or contact us using Slack.